Chapitre 2 Introduction aux data sciences
L’objet du manuel est de donner un aperçu général des méthodes d’analyses de données et de data sciences Mais avant de s’engager dans les procédures une réflexion épistémologique et historique peut être utile. Si les méthodes sont puissantes, inventives, ils faut aussi s’interroger sur leur conditions d’émergences. La discipline fût la statistique, elle alimenta milles champs spécifiques : économétrie, psychométrie, biostatistiques. Derrières les problèmes l’avance des mathématiques pour caractériser les modèles proposés. Elle s’est laissée aller à d’autres terminologies : analyse des données, data mining, Machien learning, deep learning.
2.1 Science, art, technique et pratiques
Plutôt que le terme consacré de data sciences, il vaudrait mieux parler de data ingénierie dans la mesure où le data scientiste participe à un processus de production qui va de l’acquisition des données à leur propagation dans l’organisation ou la société. La technique domine sur la science et l’unité se trouve dans l’intégration de ce processus. La révolution des données vient de l’interopérabilité croissante de ces techniques et d’une intégration qui fluidifie le passage d’une étape à une autre. Standards et langages en sont les éléments clés.
Du côté des sciences, ce dont bénéficie l’univers des data sciences, c’est l’héritage de cultures statistiques foisonnantes qui après s’être développées dans leur cocon disciplinaire, se retrouvent désormais rassemblées dans un même langage. Bien sur il y a de manière sous-jascente les mathématiques et les statistiques qui construisent les fondements des modèles et des techniques.
Mais leur développement s’est fait souvent quand le scientifique se retrouve face à un problème où une observation. Prenons le cas des psychologues qui ont inventé l’analyse factorielle dans le but de pouvoir tester certains de leurs concepts : un degré d’intelligence, une personnalité, des attitudes.
Ou celui des écologues qui souhaitent estimer une population de poisson dans une rivière, problème qui a donné naissance aux modèles de capture/recapture. On pourrait ajouter les géographes avec les modèles d’analyse spatiale, les financiers face à la variabilité des cours des places boursières, etc. Celui des économètres est peut-être le plus évident. Les biostatisticiens sont des contributeurs importants.
Ce que la technique apporte c’est l’intégration par un langage et donc un ensemble de conventions, incarnées par r et python, algorithmes, et de programmes qui ne sont plus spécifiques à un domaine, mais peuvent circuler de l’un à l’autre. C’est ainsi que le catalogues de toutes les techniques psychométriques devient accessible aux autres disciplines par le biais d’un package en particulier, psych. De la même manière l’outillage des linguiste devient accessible aux autres disciplines, pensons aux économiste qui intégrent dans le indicateurs des sources textuelle telle que l’analyse du sentiment. ( ref)
L’interopérabilité apportée par ces langages ne se définit pas que par l’algorithme qui aurait été porté d’un autre langage vers celui-ci (des cas de réécriture ?) mais aussi par des programme passerelle qui à partir de r permettent d’activité des algorithme écrit en C, en javascript ou tout autre langage “plus informatique” et souvent plus efficace.
2.2 Une courte histoires des logiciels statistiques
Ce qu’on observe dans l’évolution des logiciels
- 1980 : stat-itcf
- 1980 : SAS comme accès à r
- 1990 : SPSS
- stata
- 1997 : s dès 976 puis r, 1996 fre sofsware as r. le CRAN nait en 1997. 2003 création dez r foundation.
- 1991 - 2001: Python - Guido van Rossum - Python Software Foundation, créée en 2001
- keras
- tensor flow
http://www.deenov.com/blog-deenov/histoire-du-logiciel-spad.aspx
Un des grand mouvement du domaine est l’hésitation entre le programmatique et le no-code. La pression commerciale conduit certains acteurs à encourager l’usage de sur-couche logiciel qui débarrasse l’utilisateur de l’exigence techniques, il peut se laisser guider par l’intuition, mais l’aliène en dissimulant la mécanique profonde des processus de traitement des données.
Le succès de python et de r réside dans
- La modularisation : langage de base /fonction/ package et notion de dépendance
- L’interopérabilité pas toujours parfaite ( versions, classes de données)
- La cumulativité : les fonction s’ajoutent aux fonctions, se sédimentent
- L’accès
2.3 Le processus de traitement des données
Les data sciences ne sont finalement que l’intégration d’un flot de traitement des données qui va de l’acquisition à la divulgation.
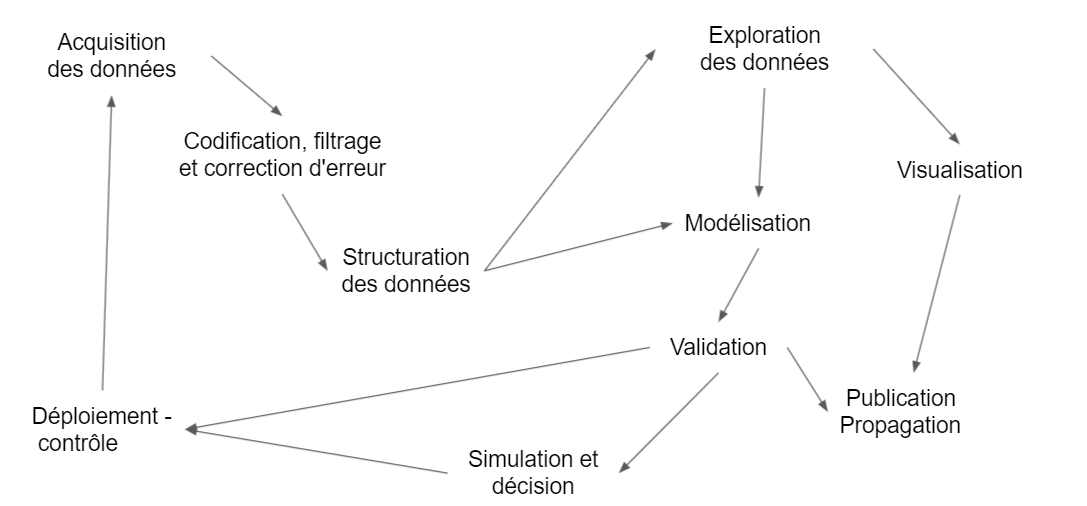
- Acquisition
- Codification , filtrage et correction d’erreur
- Structuration des données : api, open data
- Exploration
- Modélisation :
- validation : tests versus AB testing
- Simulation et décision
- Vizualisation et sensemaking
- Déploiement :
- Contrôle :
- Publication : dash board, pdf , slide etc, webb site
2.4 Les facteurs sociaux du développement des datasciences
Ces développements sont favorisés par un environnement fertile dont quatre facteurs se renforcent mutuellement. La constitution d’un système de communication commun organisé autour de peu de langage, et d’un ensemble de normes de données mais aussi la vitalité d’une communauté. La multiplicité des sources de données et l’évolution des technologies de la mesure et du nombre constitue un second groupe de facteurs.
2.4.1 Une lingua franca
La lingua franca est la langue des ports et du commerce de la méditerranée au XIVème siècle, un mélange de langage qui sert l’échange, un commun pourrait-on dire aujourd’hui. C’est ce que sont devenus python et r parmi d’autres, la seconde langue après l’anglais qui s’est imposé comme la langue d’écriture. Le langage des scientifiques est sans doute désormais un pidgin, un créole d’anglais, et de r ou de python, sans compter les sparc, les C+++ ou javascript. Les langues de la donnée se mêlent volontiers, elle sont de plus en plus agnostique.
L’environnement r par exemple devient de plus en plus ouverts à python, à la fois de manière directe en permettant de coder dans un même document des calculs en r pluis en python, mais aussi de manière indirecte parce que prolifèrent des packages passerelles permettant d’aller chercher des ressources écrites dans un autre langage.
2.4.2 Une communauté
Le second facteur, intimement lié au premier, est la constitution d’une large communauté de développeurs et utilisateurs qui se retrouvent aujourd’hui dans des plateformes de dépôts (Github, Gitlab), de plateformes de type quora (StalkOverFlow), de tutoriaux, de blogs (BloggeR), de journaux (Journal of Statistical Software) et de bookdown. Des ressources abondantes sont disponibles et facilitent la formation des chercheurs et des data scientists. Toutes les conditions sont réunies pour engendrer une effervescence créative.
Cette communauté se reproduit à petite échelles dans les procédures de laboratoire et les conventions de travail en commun des chercheurs. Elle peut se développer autant verticalement qu’horizontalement : des hubs qui concentrent l’ensemble des acteurs et des ressources, qu’un grand nombre de micro communauté focalisés sur des problèmes très locaux.
2.4.3 La multiplication des sources de données.
Le troisième est la multiplication des sources de données et leur facilité d’accès. Les données privées, et en particulier celles des réseaux sociaux, même si un péage doit être payé pour accéder aux APIs, popularisent le traitement de données massives.
Le mouvement des données ouvertes (open data) proposent et facilitent accès à des milliers de corps de données : retards de la SNCF, grand débat, le formidable travail de l’Insee, european survey etc.
2.4.4 de la statistique à l’IA
Le retour au boites noires dans les années 2000. Ce qui distingue les statistiques traditionnelles de l’approche machine learning réside d’abord par une approche de la modélisation différente.
Les modèles statistiques et économétriques considèrent une structure de relation, la spécification du modèle (ex : le modèle linéaire), mais aussi des modèles de distribution des erreurs qui définissent le cadre d’estimation. L’évaluation passe par le test des hypothèses sur les paramètres et par la qualité d’ajustement.
Le machine learning, se concentre sur la valeur prédictive, et considère n’importe quelle spécification même si elle est peu intelligible et comprend de grandes quantités de paramètres sur lesquels aucun test n’est produit.
Les deux approches ont plutôt tendance à ce compléter, les première testant des théories, les secondes procurant aux première de nouvelles hypothèse par de nouvelle mesure. Pour en donner un exemple simple, l’analyse de sentiment emploie des modèles complexes pour le prédire avec le seul texte, l’IA permet d’enrichir des données empiriques par exemple en testant en finance la relation de cet indicateurs aux prix de marché. Un autre exemple en marketing.
Les méthodes disponibles se sont accumulées depuis ces dernières 20 années. faisons-en une courte liste.
- 1956 :perceptron
- 1963 : arbre de décision
- 2005 : CNN
- 2008 : lda topic
- 2013 : word2vec
- 2018 : transformers
- ….
KNN, SVM, rf et le retour des réseaux de neurones.
2.5 Conclusion
Il ne reste plus qu’à soulever le capot et de mettre les mains dans le cambouis.
Et à se rappeler que si la nécessité de se faire remarquer à conduit les acteurs du domaine à envisager des data sciences, que c’est d’abord un art d’écriture, et une pratique qui permet à leurs artisans de s’échanger des secrets de fabrique.
On remerciera tous ceux qui développent des Packages, nous aurons le point de vue de ceux qui les utilisent. Ce cours est aussi un livre de recette, celui d’un chercheur en sciences sociales qui picore dans l’immensité de la production pour trouver des procédures reproductibles par ses étudiants.