Chapitre 8 Analyse du sentiment
A vrai dire l’analyse du sentiment telle qu’on va la développer dans ce chapitre est une méthode d’annotation comme celle qu’on a examinée précèdemment. Son principe est simple : on compte la fréquence de mots qui appartiennent à un dictionnaire de réfrences. Les différentes méthodes dépendent de la constitution de ces dictionnaires. Dans certains cas on peut nuancer en prenant en compte les modificateurs (notamment les négation et double négation) qui pourront pondérer le sentiment primaire des mots.
liu ping est le fondateur de l’analyse du sentiment et dès 2012 en donne une synthèse complète (Liu 2012) . Depuis des développement considérables ont été apportée par des méthodes de deep learning, et notamment les modèles transformer qui renouvelent consirablement le domaine.
On restera ici à un niveau classique ou compositionnel et On travaillera sur un corpus d’avis trip advisor, sur la période avant covid. Un premier exemple se concentrera sur le comptage des termes positifs, négatifs et neutres. Dans un second on montre une généralisation avec le LIWC qui propose 80 catégories.
8.1 Un exemple avec syuzhet
On utilise le package syuzhet et en particulier le dictionnaire “nrc” developpé et traduit par Mohammad and Turney (2013) ( Index Feel)
Le même outil fournit un autre systéme d’annotation qui compte les mentions d’éléments positifs ou négatifs, ainsi que d’émotions définies sur la base de l’inventaire de Plutchik (1982) on utilise simplement la fonction get_nrc_sentiment, en précisant le dictionnaire adéquat. L’échelle comprend en fait deux éléments : les 8 émotion de base *au sens de pluchik, et deux indicateurs de polarité.
L’opérationnalisation réalisée par Mohammad and Turney (2013) s’inscrit dans une tradition de la recherche en marketing, se souvenir de (???) et de (???).
library(syuzhet) #analyse du sentimeent
#paramétres
method <- "nrc"
lang <- "french"
phrase<-as.character(paste0(df$Titre," ",df$Commetaire))
#extraction
emotions <- get_nrc_sentiment(phrase,language = "french")
polarity<-subset(emotions,select=c(positive, negative))
df<-cbind(df,polarity)On s’intéresse surtout aux mentions positives et négatives (les émotions c’est pour plus tard. (la mesure permet ainsi une dissymétrie des deux polarités, il y a le bien, le mal, le mal et le bien, mais aussi si qui n’est ni mal ni bien). Les textes étant inégaux en taille on va ramener l’indicateur de polarité au nombre de caractéres (sur une base de 500 c) de chaque contribution. En effet l’algo compte les valence et leur intensité est proportionnel à la longueur du texte. Ce qui est clairement démontré par la seconde figure.
A partir de ces deux mesures, 4 indicateurs peuvent étre construits * Positivité : nombre de termes positifs pour 500 signes. * Négativitivé : nombre de termes négatifs pour 500 signes. * Valence : rapport du nombre de termes positifs sur les négatifs. * Expressivité : nombre de termes positifs et négatifs. le dernier graphe nous apprend que les jugements plutôt positifs sont aussi les plus expressifs. La “froideur” des avis les plus négatifs refléte-t-elle une crainte de la désaprobation sociale. C’est une piste de recherche à poursuivre, on pourrait s’attendre à ce que les avis les plus négatifs surgissent plus facilement si la densité des négatives est plus importante et observer une sorte d’autocorrélation.
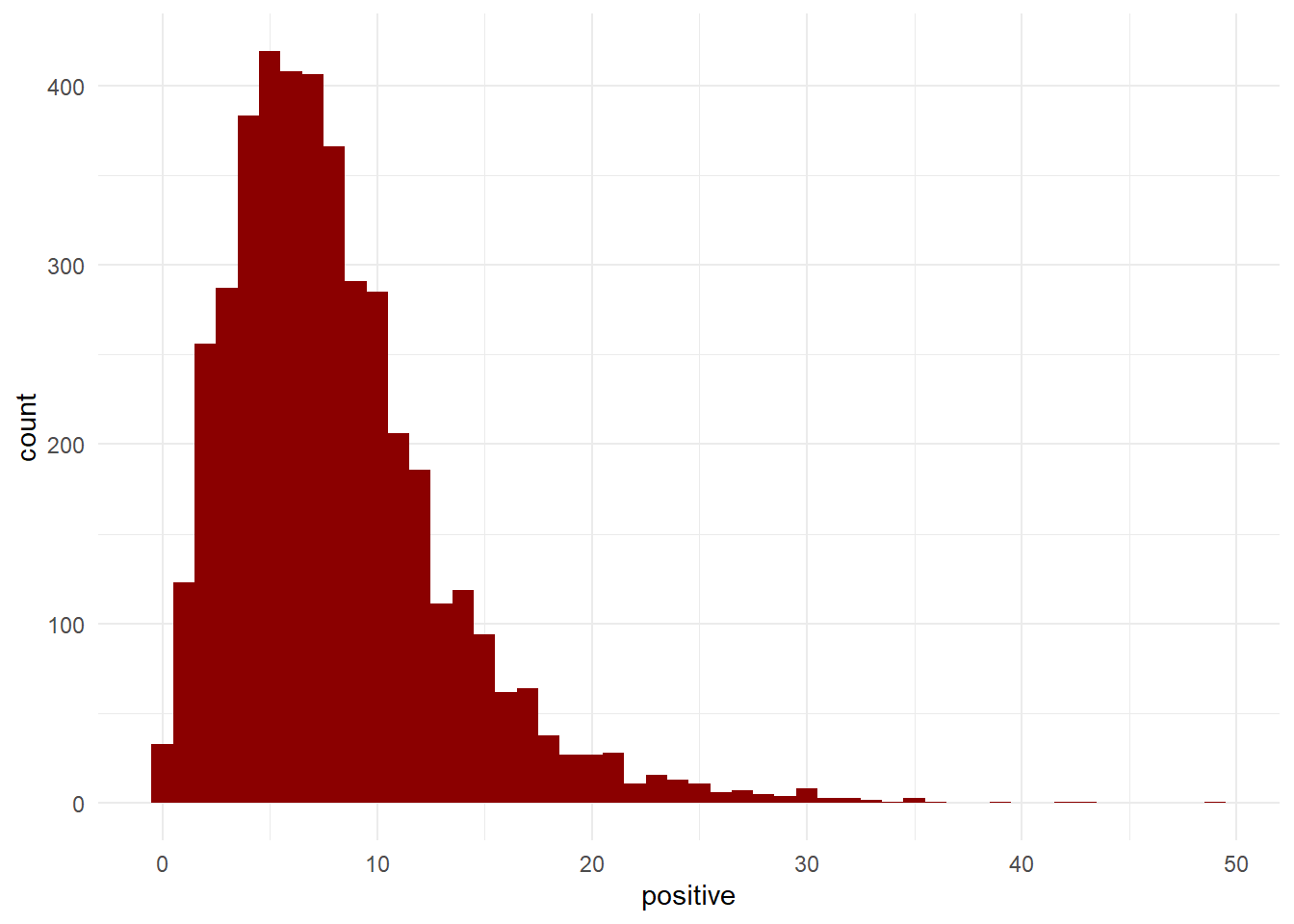
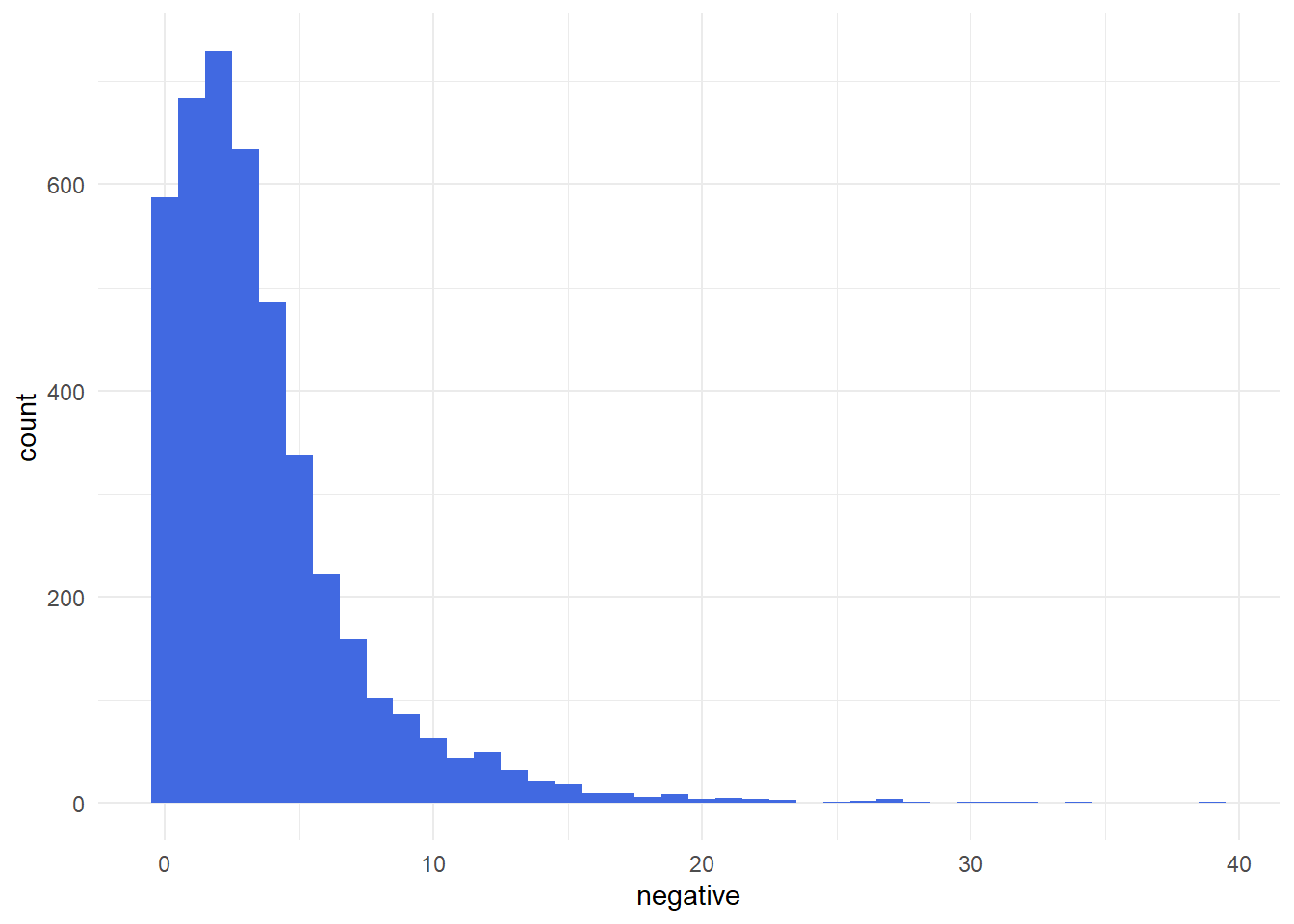
8.1.1 Valence et expression
la linguistique donne aux mots une valence : elle peut être positive (bonheur), négative (malheur) ou neutre ( tranquité).
C’est un régime ternaire. Chaque mot d’une phrase est neutre, positif ou négatif.
On peut doser les effets
On a des dictionnaires
df$text<-as.character(paste0(df$Titre," ",df$Commetaire))
df$WC<-str_count(df$text, "\\S+")
df$positivity<-(df$positive)/(df$WC)
df$negativity<-(df$negative)/(df$WC)
df$valence<-df$positivity-df$negativity
df$expressivity<-df$positivity+df$negativity
G11<-ggplot(df, aes(x=valence,y=expressivity ))+geom_point(color="grey")+geom_smooth(method = "gam", formula = y ~ s(x, bs = "cs"))+theme_minimal()
G12<-ggplot(df, aes(x=negativity,y=positivity ))+geom_point(color="grey")+geom_smooth(method = "gam", formula = y ~ s(x, bs = "cs"))+theme_minimal()
G13<-ggplot(df, aes(x=negativity,y= expressivity))+geom_point(color="grey")+geom_smooth(method = "gam", formula = y ~ s(x, bs = "cs"))+theme_minimal()
G14<-ggplot(df, aes(x=positivity,y= expressivity))+geom_point(color="grey")+geom_smooth(method = "gam", formula = y ~ s(x, bs = "cs"))+theme_minimal()
plot_grid(G11, G12, G13,G14, labels = c('A', 'B', 'C','D'))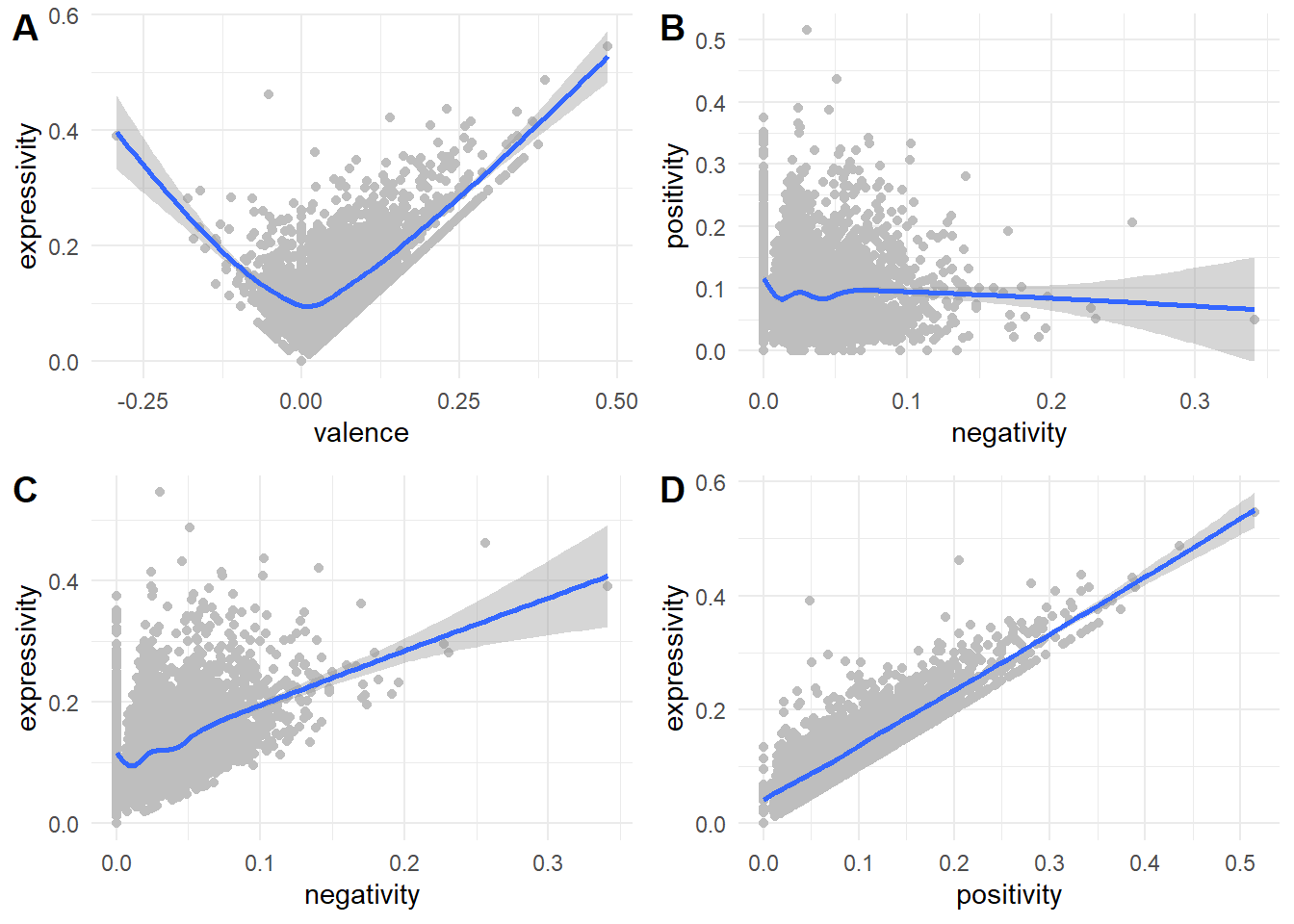
8.2 La généralisation par le Liwc
Le liwc vient de l’idée simple d’un psychiatre qui a souhaité faire des diagnoistics de trauma craniens à partir des entretiens menés avec lmes patients atteints. (Tausczik and Pennebaker 2010)
Le LIWC permet d’obtenir d’autres indicateurs du sentiment, une partie des 80 indicateurs proposés est relatif à des dimensions topicales dont trois groupes vont retenir notre attention dans la mesure où ils décrivent une partie de l’expérience relatée dans les commentaires. * La sensorialité ( voir, entendre, sentir) * L’orientation temporelle ( passé, présent, futur) * les émotions négatives (tristesse, colére, )
La procédure pour extraire ces notions est fort simple . On utilise l’infrasturure de quanteda et une version francophone du dictionnaire (Piolat et al. 2011)
# the devtools package needs to be installed for this to work
#devtools::install_github("kbenoit/quanteda.dictionaries")
library(cleanNLP)
library("quanteda.dictionaries")
dict_liwc_french <- dictionary(file = "FrenchLIWCDictionary.dic",
format = "LIWC")
test<-liwcalike(df$Commetaire,dictionary = dict_liwc_french)
df<-cbind(df,test)8.3 Encore d’autres généralisations
L’approche par dictionnaire s’est déplacée vers l’identification d’autre catégorie
- les valeurs morales
8.4 construire son propre dictionnaire
faire des listes de lmots
References
Liu, Bing. 2012. “Sentiment Analysis and Opinion Mining.” Synthesis Lectures on Human Language Technologies 5 (1): 1–167. https://doi.org/10.2200/S00416ED1V01Y201204HLT016.
Mohammad, Saif M., and Peter D. Turney. 2013. “CROWDSOURCING A WORD-EMOTION ASSOCIATION LEXICON.” Computational Intelligence 29 (3): 436–65. https://doi.org/10.1111/j.1467-8640.2012.00460.x.
Piolat, A., R. J. Booth, C. K. Chung, M. Davids, and J. W. Pennebaker. 2011. “La Version Française Du Dictionnaire Pour Le LIWC : Modalités de Construction et Exemples d’utilisation.” Psychologie Française 56 (3): 145–59. https://doi.org/10.1016/j.psfr.2011.07.002.
Plutchik, Robert. 1982. “A Psychoevolutionary Theory of Emotions.” Social Science Information 21 (4-5): 529–53. https://doi.org/10.1177/053901882021004003.
Tausczik, Yla R., and James W. Pennebaker. 2010. “The Psychological Meaning of Words: LIWC and Computerized Text Analysis Methods.” Journal of Language and Social Psychology 29 (1): 24–54. https://doi.org/10.1177/0261927X09351676.