Chapitre 12 Le retour des méthodes factorielles
12.1 Objectifs du chapitre
L’objectif de cette partie est de revenir sur des méthodes traditionnelles mais toujours efficace d’analyse lexicale souvent combiné à des méthode de classification.
comprendre le fonctionnement des différentes techniques de réduction de grands ensembles de données. Leur principe reste de réussir à exprimer sous forme de facteur(s), un ou plusieurs concepts non observés, latents, ou d’intérêt. Ces méthodes de calculs feront l’objet d’une description générale, abordant les sous-bassements statistiques utilisées dans un cas pratique avec un dataset de tweets obtenu par rtweet ( voir chapitre 3).
Trois algorithmes utilisés en analyse factorielle seront abordés :
- Analyse par Composante Principale (PCA)
- Analyse Factorielle des Correspondances (AFC)
- La Classification Hiérarchique (CHA/CHD)
- Introduction à Reinette
- Introduction à Wordfish
12.2 Les outils
Les packages permettant de mener les analyses ci-dessous sont FactoMineR et factoextra. Les heat map utilisées pour parvenir au clustering de l’analyse des correspondances sont issues du package NMF ou encore quanteda
12.3 Introduction
Si les méthodes factorielles ont été développées dès 1904 par le psychologue Charles Spearman pour comprendre comment les variables dans une ambition plus confirmatoire et hiérarchique, les méthodes factorielles se sont popularisées sous les travaux de Benzecri, permettant un élargissement de son usage. (???)
Elles se sont progressivement diluées dans la “boîte à outils” des différentes disciplines académiques. Ces principes de fonctionnement et autres calculs originels ont été confrontés à diverses sources et structures de données, que notre environnement de plus en plus numérique à amener à générer. (???)
L’interaction avec ces interfaces mathématiques sont aujourd’hui largement informatisées, et le travail de l’analyste se complète également par le devoir de savoir expliciter ces “sorties logicielles”.
12.4 Méthodes & Données
12.4.1 Principes généraux
L’idée essentielle est qu’un objet peut-être décrit par un ensemble d’attributs observables et en ce sens, mesurables. Des relations peuvent exister entre les \(p\) variables précitées, entre chaque individu \(n\) observé, dans une base de données.

Mathématiquement parlant, le développement accru des travaux de recherche repose sur des questions comme :
- Le caractère unique ou multiple des facteurs / concepts sous jacents que l’on souhaite utiliser pour résumer les données, ou bien encore sur les modalités de calculs, liéaires ou non, des combinaisons factorielles souhaitées.(???) Les Lois de distribution utilisées pour approcher ces différentes sources de données diffèrent et sont à l’origine de la diversification des algorithmes. (???)
L’idée principale est de trouver \(k\) combinaisons linéaires des \(p\) variables qui capturent succéssivement une part maximale de la variance, ce qui minimise réciproquement l’écart total d’erreurs, d’un effectif \(n\) d’observations, tel que \(k << p\). Cette mécanique de synthèse repose sur le théorème de la Décomposition en Valeurs Singulières des matrices (SVD), tels que pour toute \(X_{(n,p)}\) :
\[ X=\mathbf{U}\mathbf{D} \mathbf{V}^\top \]
\(U_{n}\) Une matrice carrée tel que : \(U=n\) x \(n\) ; \(v=p\) x \(p\) et ; \(D\) de dimensions \(k\) x \(k\), dont la diagonale \(D_{(i,i)}\) comporte les valeurs des eigenvectors \(\lambda_{n}\) calculés par les algorithmes factoriels.
Dans le domaine de l’analyse d’éléments textuels ce tableau correspond au document-term-matrix (dtm) et document-feature-matrix (dfm), où les “individus” sont alors considérés en tant que documents (tweets, reviews, litteratures…) auxquels nous rattachons en colonne, les termes, afin d’en compter chaque occurence.
12.4.2 Données
Nous avons scrappé via le package rtweets un ensemble de 4 hashtags : javascript, Cobol, Python, Java, selon les méthodologies robustes de construction de corpus déjà éprouvées(???)
On peut supposer a priori que les communications autour des langages de programmation soient similaires et uniformes, dans une première proposition relevant du marketing des technologies N/TIC.(???)
###LECTURE DES FICHIERS
df <- readRDS("data/Data_info.rds")
df <-df %>% mutate(filtre =ifelse(str_detect(text,"cocaine|shit"), 1, 0))
table(df$filtre)##
## 0 1
## 1930 217
La répartition des tweets primaires pour chaque langage varie de 70% à 15%. Cette première observation peut justifier que l’on souhaite étudier plus en détails le rôles de certaines variables dans les effets de diffusion.
Une première idée est que les communautés et les modes d’apparitions de ces langages étudiés sur Twitter semblent, sur l’échantillon donné, singuliers.
12.5 Analyse par Composantes Principales (ACP/PCA)
L’ACP et ses dérivées appliquées à des données de comptage comme l’AFCM sous l’influence de J. Benzecri, ont longtemps étés les méthodes “reines”, et restent aujourd’hui, toujours les plus fréquemment utilisées.
Historiquement elle a été développée pour analyser des matrices de corrélations multiples où, \(X\) est une matrice de \(n\) d’individus et \(p\) de variables suivant une loi de distribution Gausienne.
Notre travail ici est donc de chercher à savoir si les caractéristiques des comptes (Nombres de Tweets,followers,posts,Maturité,amis,Caractères produits) traduisent une éventuelle présence différenciée.
On sélectionne un sous ensemble de données quantitatives et l’on calcule volontairement ici deux nouvelles variables dépendantes : le volume total de caractères produit sur la plateforme pour un internaute ainsi que la somme de ses tweets.
###On crée un sous ensemble de données quantitatives, que l'on regroupe par Marque et Screen name
df_pca <- df %>%
select(Marque,screen_name,DureeV,retweet_count,followers_count,friends_count,statuses_count,display_text_width)
df_pca$score <- 1
###On Crée deux nouvelles variables naturellement auto-corrélées : Total de caractère et total tweets sur la période.
df_pca <- df_pca%>%
group_by(Marque,screen_name)%>%
summarise(DureeV,followers_count,friends_count,statuses_count,Totalcr=sum(display_text_width),Totaltwt=sum(score),retweet_count)
foo <- flextable(df_pca[sample(nrow(df_pca), 20), ])
foo <- add_footer_lines(foo, "Exemple de 20 lignes échantillonnées au hasard")
fooMarque | screen_name | DureeV | followers_count | friends_count | statuses_count | Totalcr | Totaltwt | retweet_count |
Python | Nicoolaouici | 34 | 4 | 21 | 125 | 35 | 1 | 0 |
Java | 3615sauvane | 51 | 21,307 | 932 | 25,884 | 263 | 1 | 9 |
Java | RemyBaho | 14 | 3,064 | 258 | 15,232 | 180 | 2 | 0 |
Java | nelisiane | 35 | 199 | 181 | 5,031 | 76 | 1 | 0 |
Java | GoodGrief_GANG_ | 4 | 32 | 132 | 2,511 | 12 | 1 | 0 |
Cobol | _adriend_ | 57 | 1,687 | 220 | 14,144 | 115 | 1 | 0 |
Python | dufour_matisse | 3 | 15 | 51 | 241 | 123 | 1 | 0 |
Python | carlosmdelc | 73 | 349 | 3,449 | 3,965 | 15 | 1 | 0 |
Java | Doxyaxone | 24 | 2,063 | 4,396 | 10,810 | 1,114 | 4 | 7 |
Java | BCanaple | 52 | 514 | 479 | 31,645 | 216 | 1 | 0 |
Java | dnwnthsu16 | 36 | 115 | 175 | 11,509 | 22 | 1 | 0 |
javascript | faheem_khan_dev | 18 | 1,704 | 212 | 5,027 | 48 | 1 | 0 |
Java | EnricoHomann | 62 | 29 | 239 | 641 | 27 | 1 | 0 |
javascript | onasusweb | 58 | 1,497 | 1,256 | 30,554 | 10,706 | 57 | 3 |
Java | RDSca | 76 | 246,999 | 1,396 | 159,513 | 159 | 1 | 1 |
javascript | onasusweb | 58 | 1,497 | 1,256 | 30,554 | 10,706 | 57 | 4 |
Java | triooti | 51 | 482 | 56 | 2,149 | 278 | 1 | 2 |
Cobol | clochix | 72 | 1,732 | 221 | 31,954 | 278 | 1 | 1 |
Python | michellabrie404 | 33 | 28 | 60 | 1,300 | 103 | 1 | 2 |
Python | aja1979 | 70 | 3,647 | 4,847 | 35,261 | 18 | 1 | 0 |
Exemple de 20 lignes échantillonnées au hasard | ||||||||
Nous nous concentrons sur la population de comptes ayant produit des tweets retweetés au moins 19 fois. Cela représente un tableau de 2975 individus. On signale à l’ACP que la première colonne est qualitative afin qu’elle soit prise en compte dans les calculs
###MODEL PCA
df_pca_uf <- df_pca#%>%filter(retweet_count>0)
df_pca_uf$Marque <- as.factor(df_pca_uf$Marque)
###On execute le modèle
res.pca <- PCA(df_pca_uf,quali.sup = 1:2,scale.unit = TRUE, graph = FALSE,ncp =7)
###Pour les corrplot
var <- get_pca_var(res.pca = res.pca)
###Extraction des variances exprimées
fviz_eig(res.pca,
addlabels = TRUE,
ylim = c(0, 40),
main = "Pourcentage de variance exprimée selon k dimensions",
xlab = "K dimensions",
ylab = "% de variance")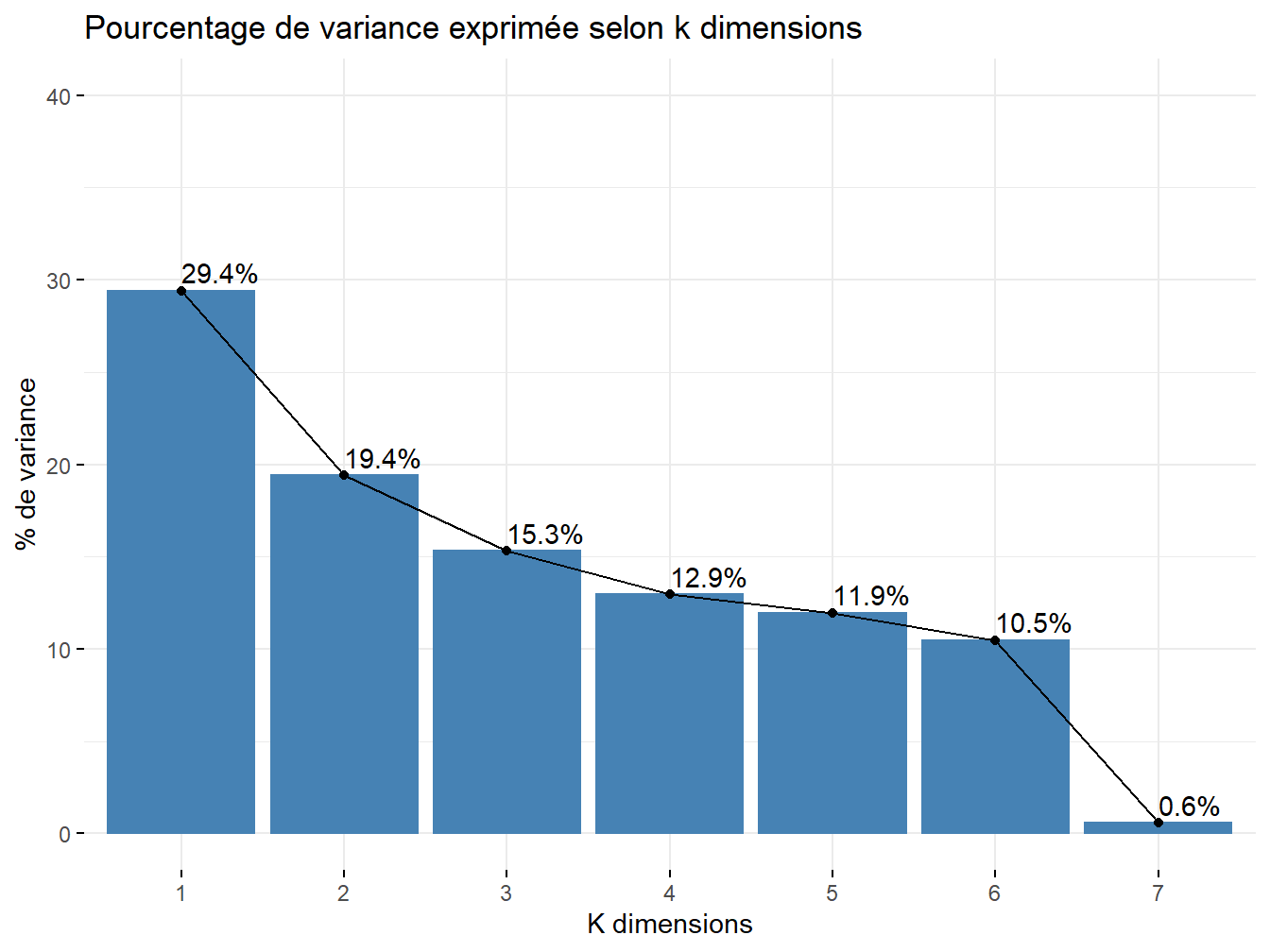
Figure 12.1: Pourcentage de variance exprimée par les dimensions
Sur cette représentation l’on voit que la somme des variances reste toujours égale à 100 %, lorsque \(k=p\).
L’intérêt est donc de savoir quels facteurs extraire. L’on souhaite donc voir plus en détails leurs évolutions au sein de l’échantillon. On décide de réaliser des matrices de covariance, corrélation et contribution.
par(mfrow=c(1,3))
corrplot(var$cos2, is.corr=FALSE,order = "hclust",sig.level = 0.01,insig = "blank")
corrplot(var$cor, is.corr=TRUE,order = "hclust",sig.level = 0.01,insig = "blank")
corrplot(var$contrib, is.corr=FALSE,order = "hclust",sig.level = 0.01,insig = "blank")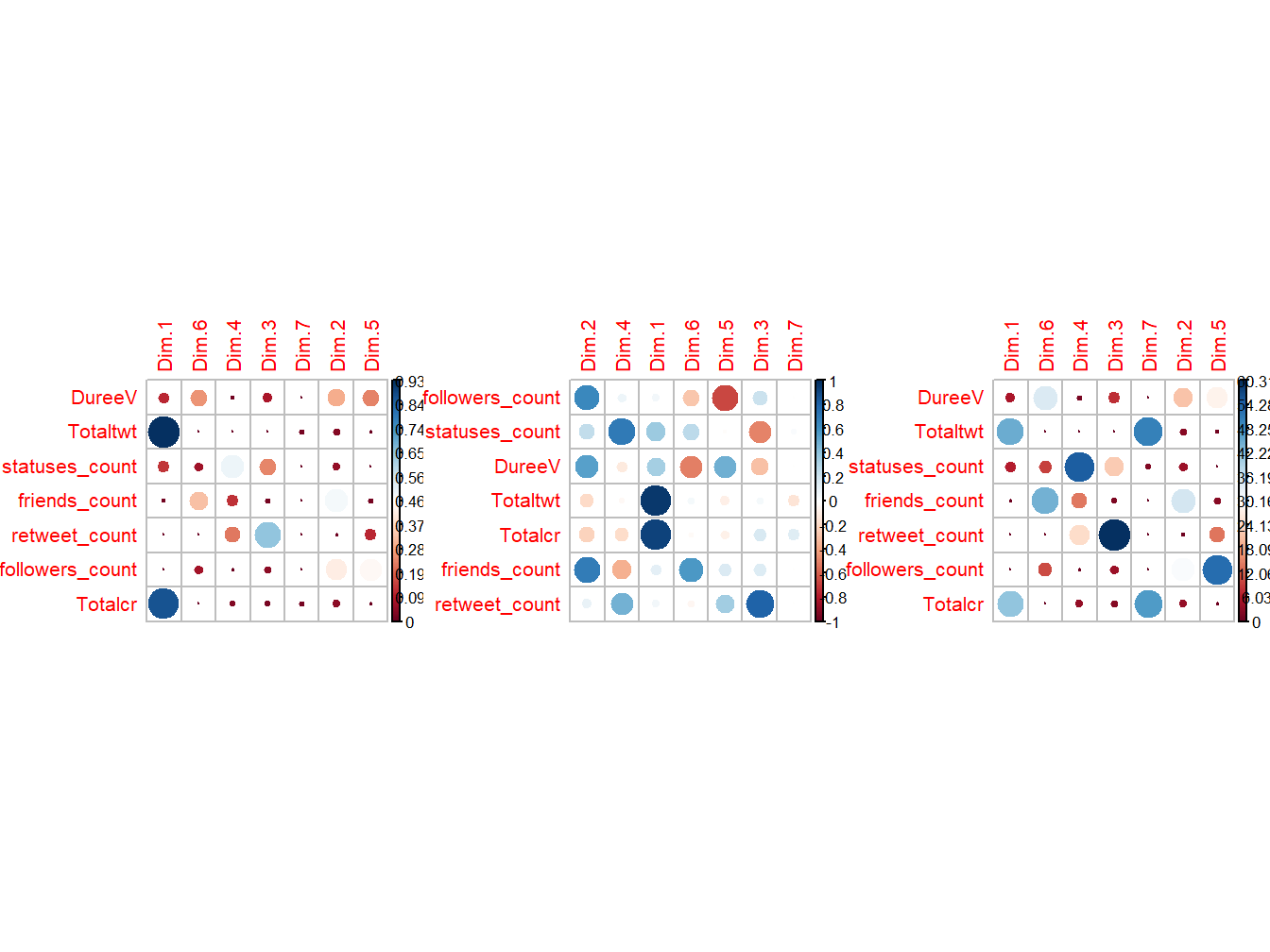
Figure 12.2: Directions, Corrélations et Contribution des Variables aux dimensions
my.cont.var <- rnorm (7)
my.cont.var.fact <- as.factor(my.cont.var)
fviz_pca_var(res.pca,
col.var = my.cont.var,
gradient.cols = c("#00AFBB", "#E7B800", "#FC4E07"),
title="Représenter l'influence des colonnes aux deux premières dimensions",
legend.title="Contrib"
)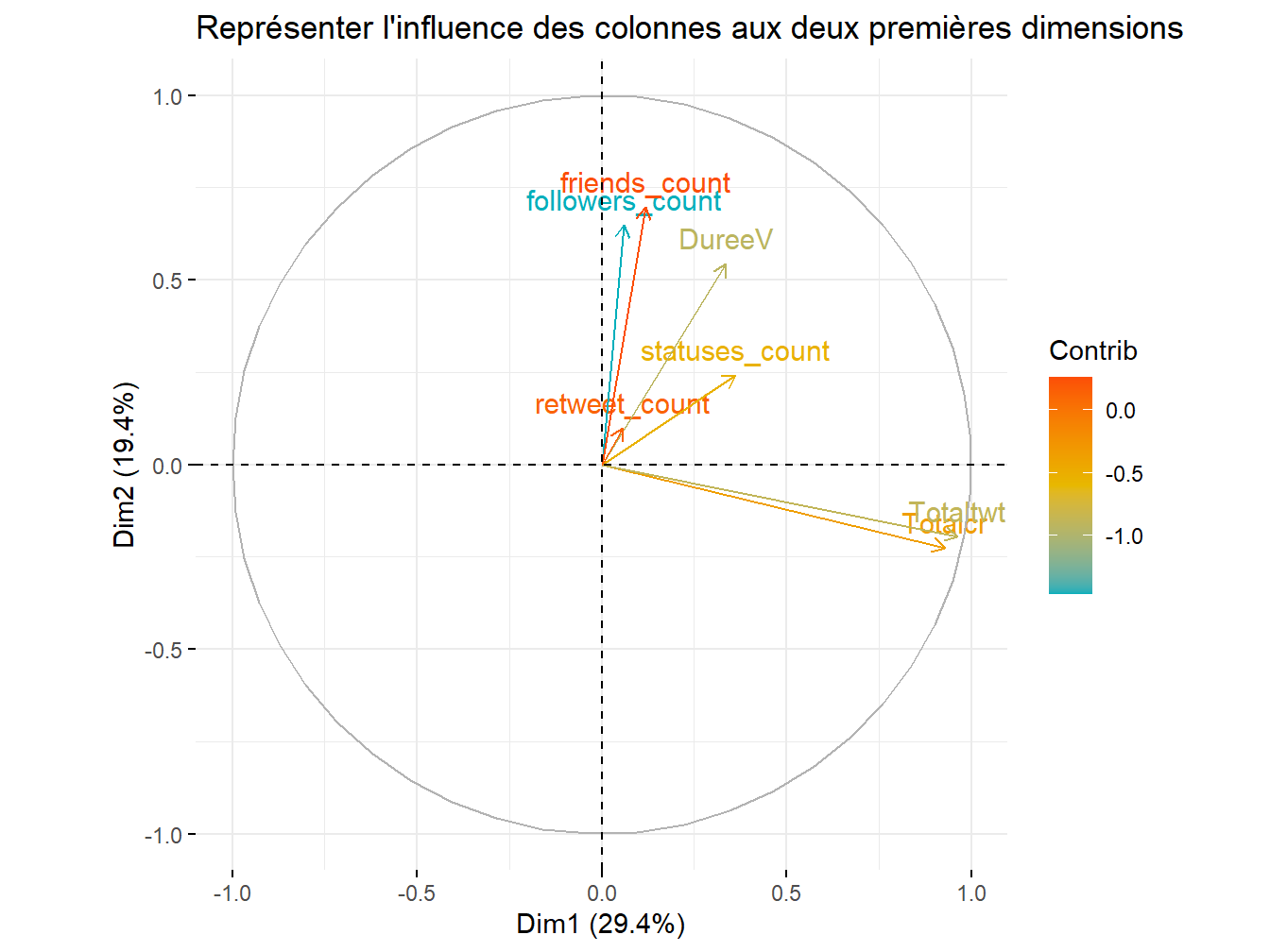
Figure 12.3: Représenter les variables
Les contributions des \(p\) variables aux \(k\) dimensions factorielles sont différenciées. A première vue, les deux variables auto-corrélées sont bien co-évolutives et presque orthogonales aux autres variables du set. On se concentre alors sur la ventilation des \(n\) individus.
my.cont.var <- rnorm (7)
my.cont.var.fact <- as.factor(my.cont.var)
fviz_pca_ind(res.pca,
geom.ind = "point", # Montre les points seulement (mais pas le "text")
col.ind = df_pca_uf$Marque, # colorer by groups
palette = c("Dark2"),
addEllipses = TRUE, # Ellipses de concentration
legend.title = "Langages",
title="Représenter une population de n individus par rapport aux deux premières dimensions"
)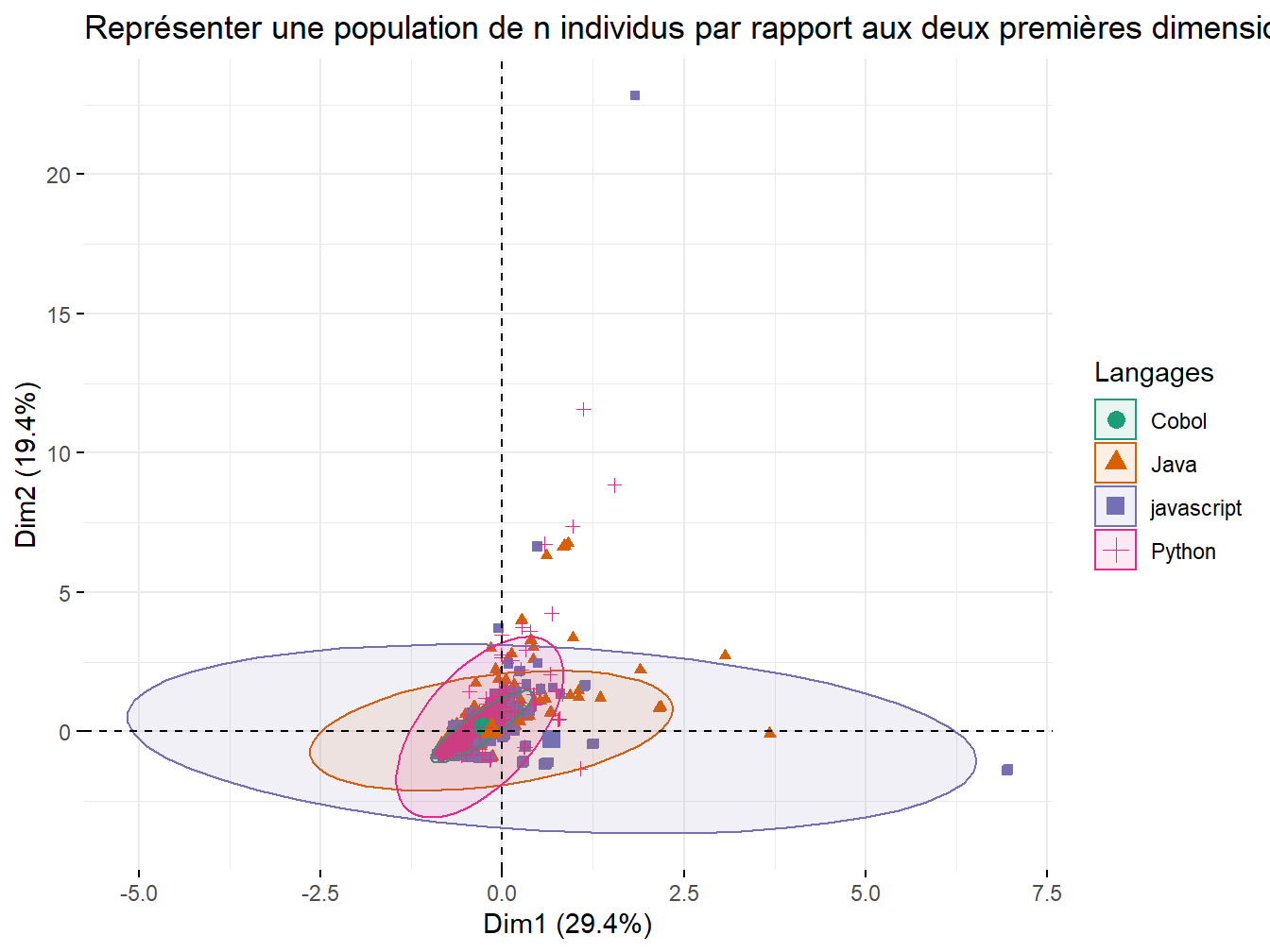
Figure 12.4: Représenter les individus
Quatre populations émergent mais restent très inégales dans leurs effectifs. En effet, les comptes mentionnant “cobol” sont nettement plus réduits.On représente alors le couple variables/individus ensemble :
fviz_pca_biplot(res.pca,label = "var",
addEllipses=TRUE,
ellipse.level=0.95,
ggtheme = theme_minimal(),
col.var = my.cont.var.fact,
title = "Individus & Dimensions",
legend.title="Coefs.Liné")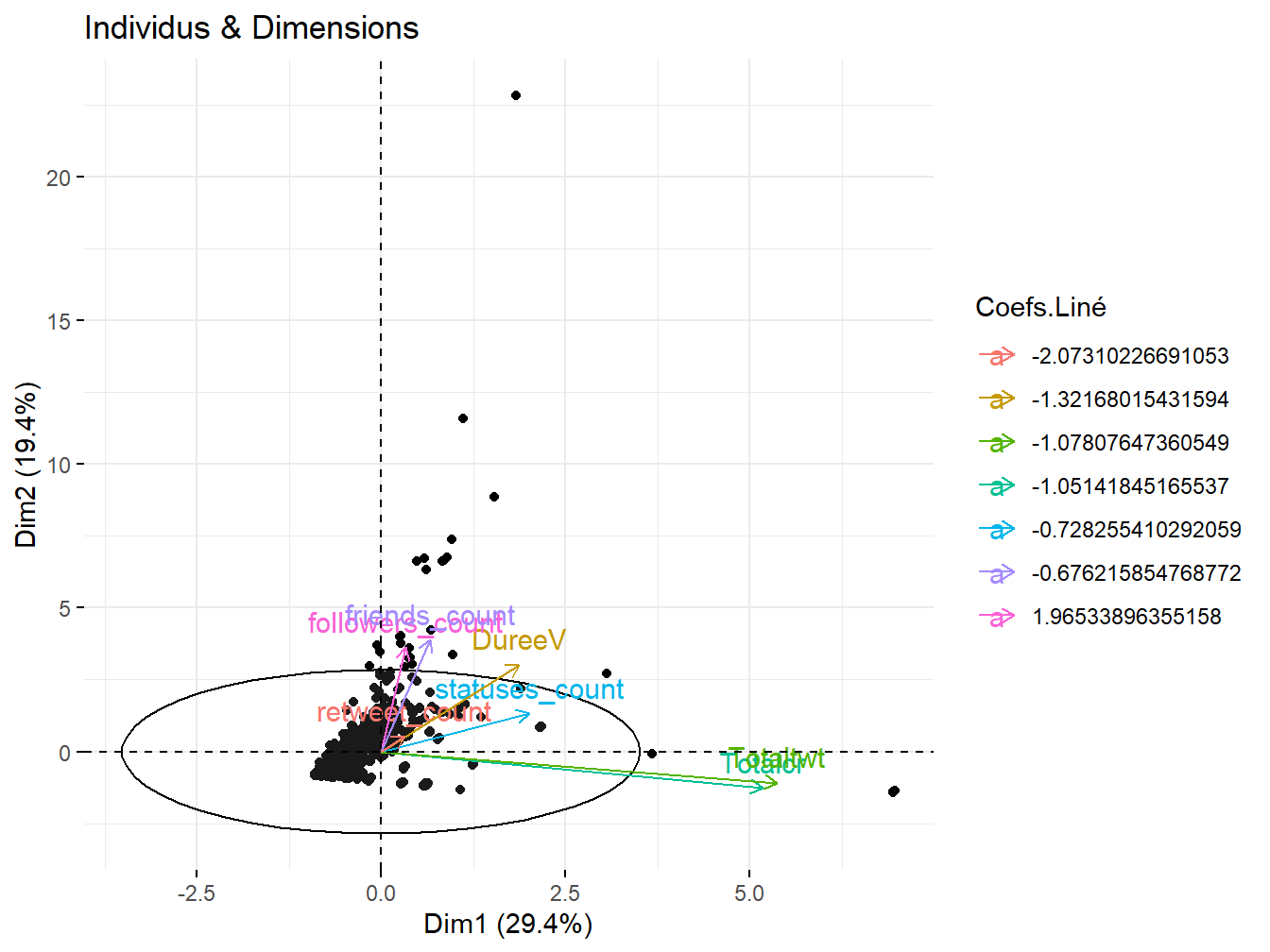
Figure 12.5: Représenter les individus et variables
Les coefficients ici visualisés peuvent être utilisés dans un modèle confirmatoire en tant que coefficients \(\alpha_{ii}\) de régression. Ce sont les éléments présentés par ordre décroissant de la diagonale de la matrice \(D\).
12.6 Analyse des Correspondances
Les bases de données Twitter étant pauvre en variable qualitatives, on travaille alors nouvellement sur les mots. Les tableaux sont dits croisés, se sont des tables de contingence entre différentes variables catégorielles.
12.6.1 Table de contingence
Le corpus est composé de 2147 tweets français et après annotation, fournit 60 360 adjectifs, noms et verbes différents. L’annotation a été réalisée selon les procédures détaillées dans le chapitre précédent.
On utilise quanteda pour regrouper les mots et produisons une document-feature-matrix que l’on transpose en term-document-matrix, considérant que les langages de programmation sont nos \(p\) variables catégorielles et les mots, nos \(n\)observations. Différentes étapes de filtrage sont nécessaire ici : suppression de la ponctuation et des liens internet.
###On charge l'annotation car nous avons utiliser un filtrage POS sur ADJ,NOM,VERB
df_trt_annot <- readRDS("data/annot_lsa_nmf.rds")
###On crée une dfm, groupant par langage et supprimant les stopwaords
dfm <- dfm(df_trt_annot$lemma,
tolower = TRUE,
what = "word",
groups=df_trt_annot$Marque,
remove=stopwords("fr"))
###On transforme l'objet afin d'obtenir une table de contingence : Mots/Langages
tdm <- as.data.frame(t(dfm))
colnames(tdm)[1] <- "Mots"
###La ponctuation est encore présente, on compte les charactères pour filtrage
tdm$char <- nchar(tdm$Mots)
###Les liens sont égalements trops présents
tdm <- tdm%>%
mutate(Off_Acc=ifelse(str_detect(Mots,"http.")==TRUE,"TRUE",
"FALSE"))
###On filtre pour éliminer la ponctuation et les liens
tdm <- tdm%>%
filter(char>1,Off_Acc=="FALSE")%>%
select(Mots,Cobol,Java,javascript,Python)
###Mnipulations pour filter et représenter les mots les plus cités pour cobol
foo <- tdm%>%
mutate(Sum=Cobol+javascript+Java+Python)%>%arrange(desc(Cobol))%>%head(20)
###Edition de la table de contingence
foo <- flextable(foo)
foo <- set_caption(foo,"Mots triés par ordre croissant sur Cobol")
fooMots | Cobol | Java | javascript | Python | Sum |
développeur | 21 | 30 | 11 | 5 | 67 |
utiliser | 13 | 10 | 10 | 12 | 45 |
aimer | 12 | 16 | 5 | 6 | 39 |
technologie | 12 | 8 | 6 | 0 | 26 |
vouloir | 11 | 10 | 4 | 8 | 33 |
langage | 10 | 20 | 7 | 24 | 61 |
avoir | 9 | 78 | 24 | 73 | 184 |
sgbd | 4 | 0 | 0 | 0 | 4 |
rigoler | 2 | 0 | 0 | 1 | 3 |
aller | 2 | 25 | 13 | 23 | 63 |
jouer | 2 | 14 | 0 | 1 | 17 |
machine | 2 | 2 | 1 | 0 | 5 |
vieux | 2 | 1 | 1 | 5 | 9 |
falloir | 2 | 11 | 3 | 12 | 28 |
mettre | 2 | 11 | 4 | 7 | 24 |
bancaire | 2 | 0 | 0 | 0 | 2 |
it | 2 | 0 | 0 | 0 | 2 |
miagiste | 2 | 0 | 0 | 0 | 2 |
parler | 2 | 7 | 3 | 5 | 17 |
indien | 1 | 0 | 0 | 1 | 2 |
On peut être amener à penser que deux mondes s’ignorent, et que des usages situés des langages s’apprécient ici via différents contextes qui leurs sont propres.
12.6.2 Modèle
A l’aide de l’analyse factorielle des correspondances, nous allons réussir à obtenir et spécifier :
La relation qu’il existe entre les individus (Mots) et les dimensions
La relation qu’il existe entre les variables (Langages) et les dimensions
La relation qu’il existe entre les individus (Mots) et les variables (Langages).
On utilise maintenant l’analyse des correspondances sur notre table de contingence :
12.6.3 explor
L’accès aux vocabulaires reste limité par une visualisation statique. Afin de pouvoir explorer dynamiquement le corpus, on privilégie la solution fournie par le package présenté ci-dessous.
###On récupère les mots de notre tdm2, filtrée et nettoyée
fviz_ca_biplot(res.ca, repel = TRUE,title = "Biplot des n Mots et p Langages")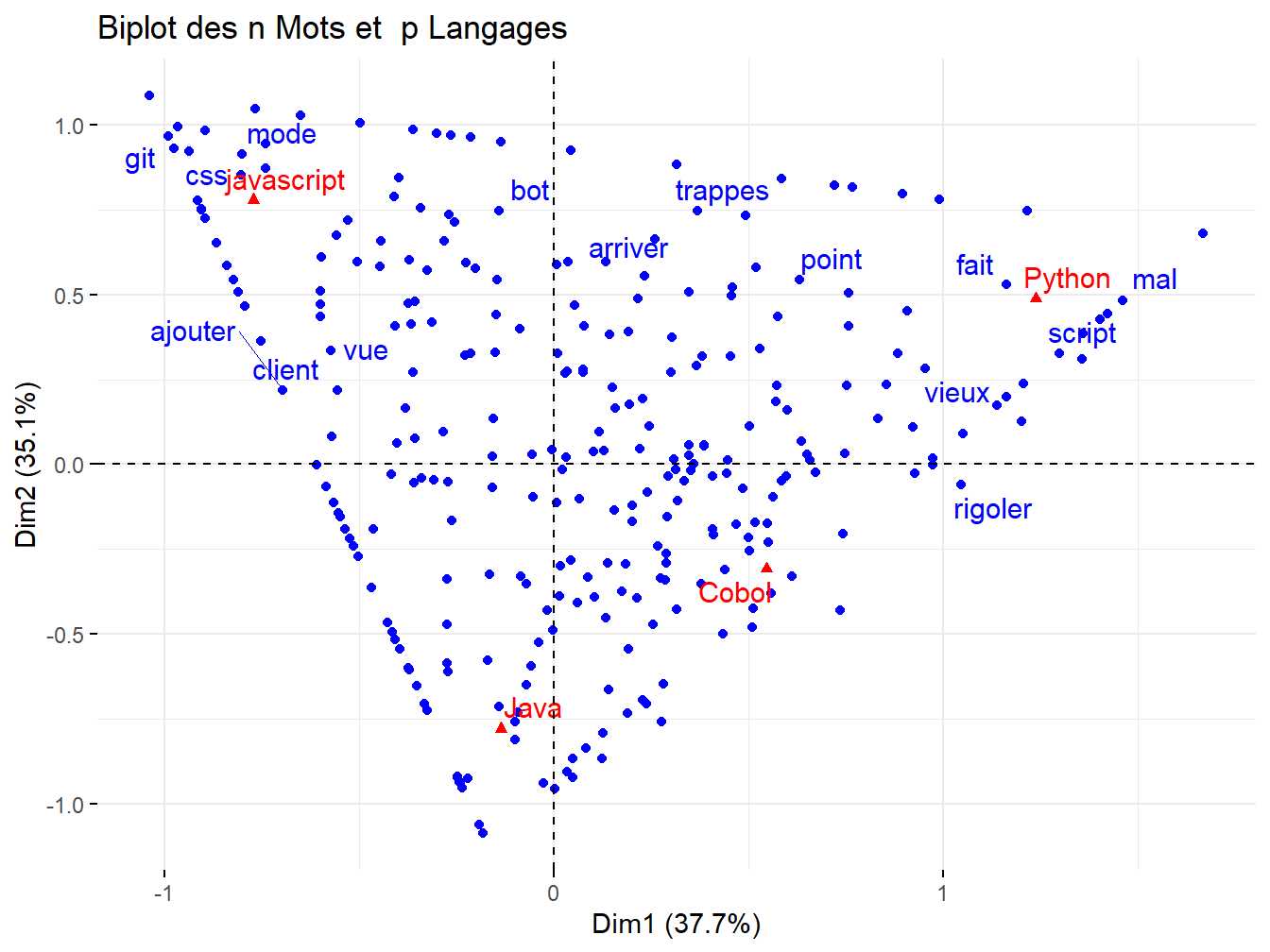
Figure 12.6: Analyse des Correspondances : Biplot Individus/variables
explor qui permet d’accélerer l’analyse exploratoire d’une fouille de données. Afin d’être représenté dans le livre, nous mettons l’éxécution dynamique de cette application shiny en commentaire.
On peut alors représenter les dimensions souhaitées, ainsi que disposer du nuage de points :
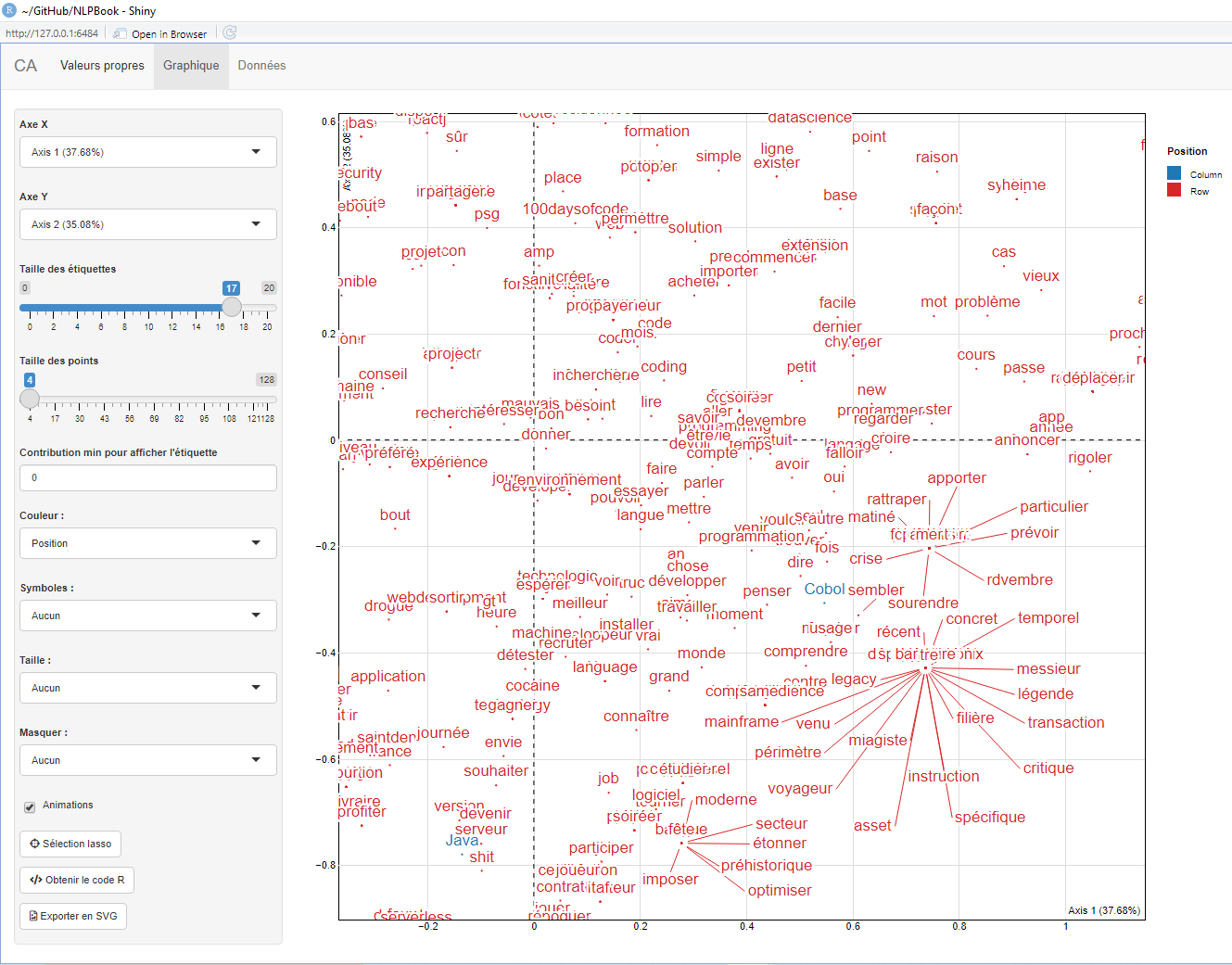
exploration
La multitude de mots ne facilite pas la lecture graphique, tout comme pour le cas des résultats pour l’ACP. Les disparités des effectifs recensés ne nous permet pas de réduire leur échantillonage, tout en conservant les spécificités de chacun. On propose donc d’utiliser des techniques de clustering, que sont les classifications hiérarchiques de types acsendantes et descendantes :
12.7 Classification Hiérarchique
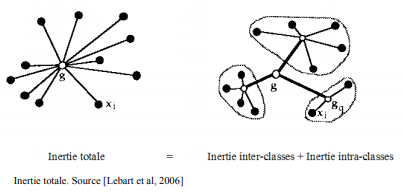
Afin de répondre à ces problèmes de saturation, et pour permettre la création de *typologies* des techniques de clustering permettent de subdiviser l’ensemble de données étudié. Ces dernières se basent sur différentes techniques de détermination. (???) Les individus d’un même groupe sont supposés avoir une variance intra-faible et une variance inter-forte avec les autres groupes, de la sorte :
12.7.1 Classification Hiérarchique Ascendante
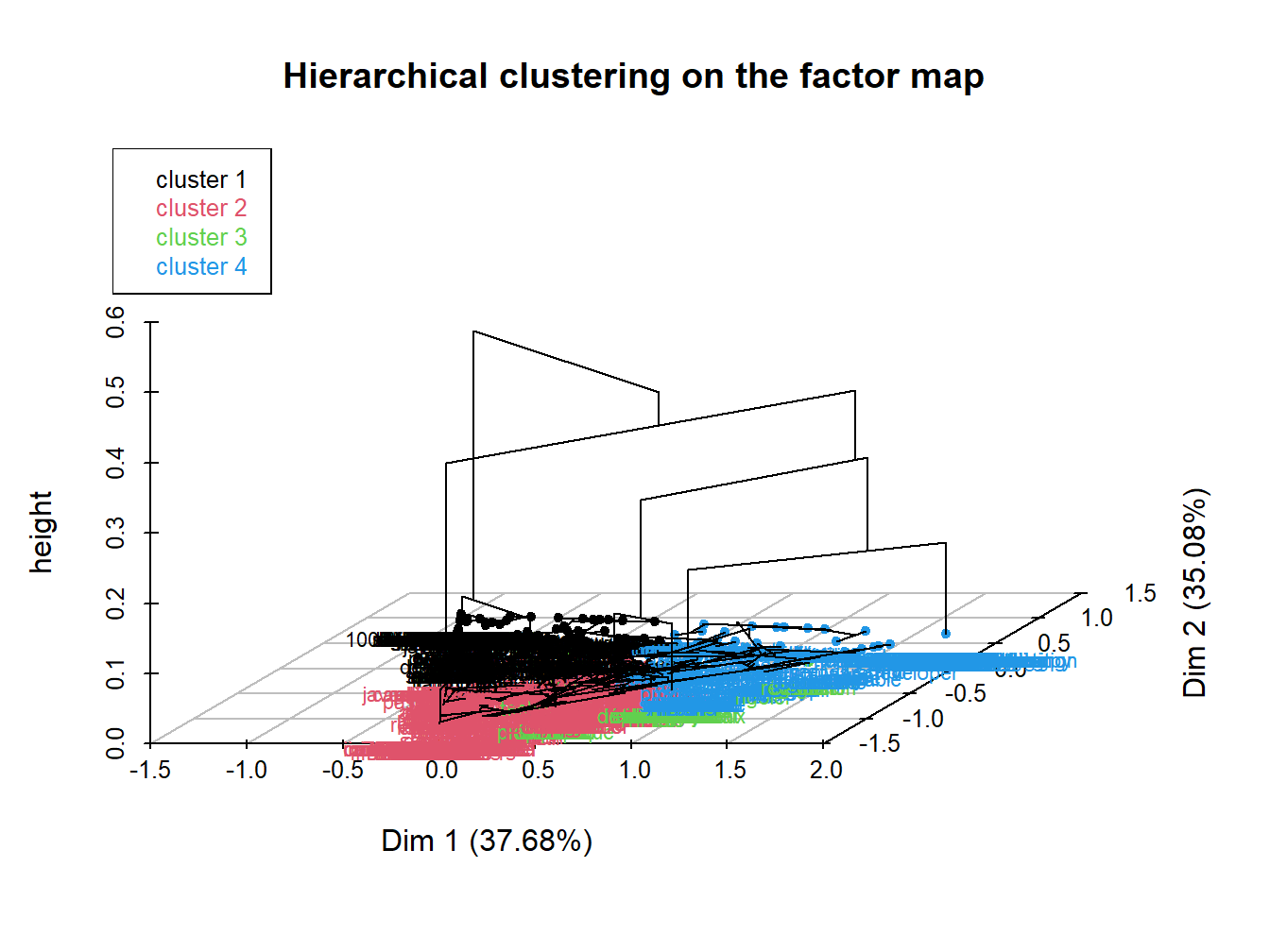
Figure 12.7: Classification Hiérarchique Ascendante des tweets
Une synthèse plus lisible des clusters est présentée ici :

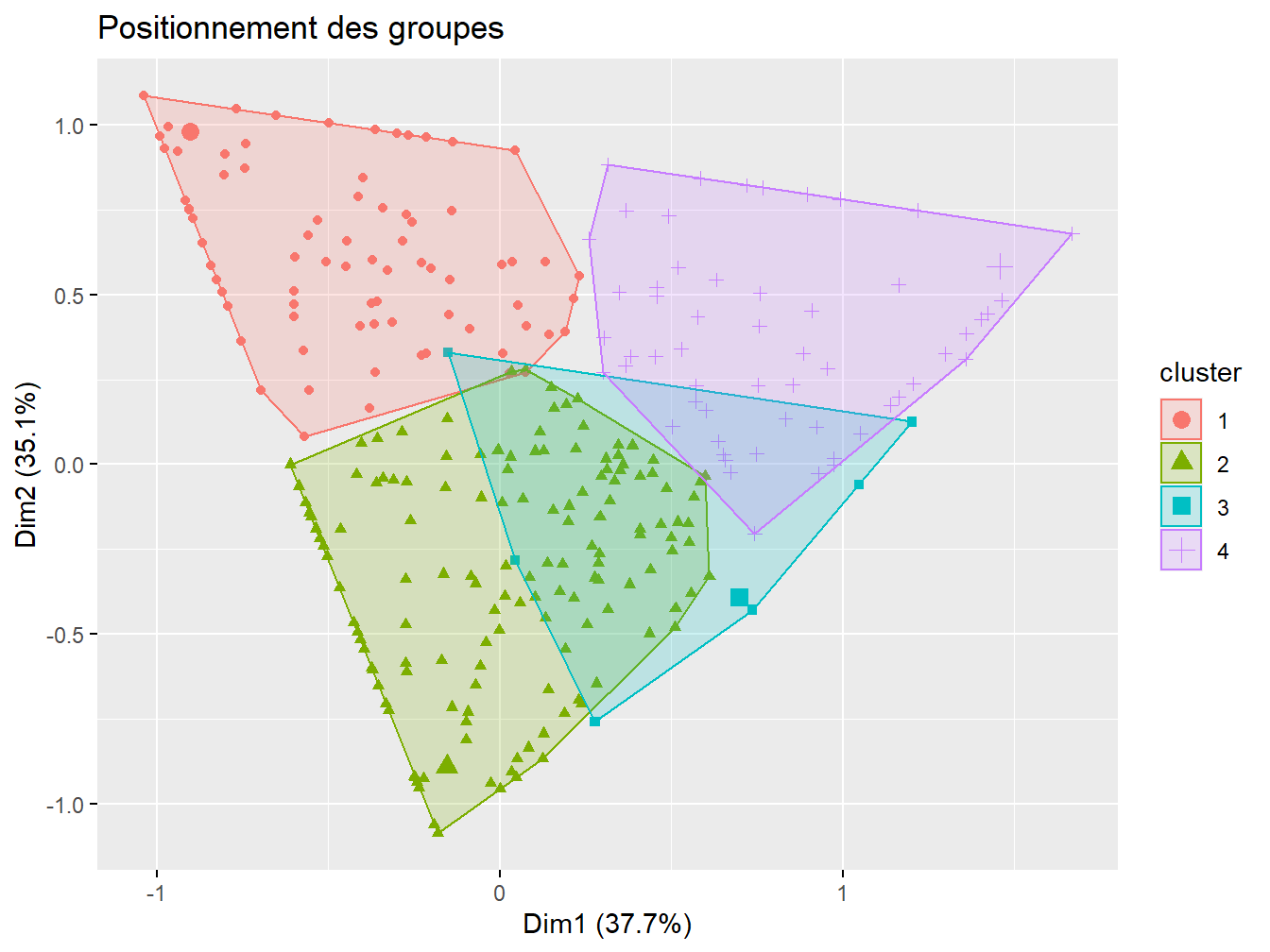
Figure 12.8: Représentation des groupes
12.7.2 Classification Hiérarchique Ascendante Double
12.7.2.1 Théorème généralisé de la décomposition en valeurs singulières
Si l’on y regarde de plus près, le résultat de l’analyse des correspondances contient deux matrices de résultats qui nous intéressent. La première, est celle des mots, associés aux dimensions.
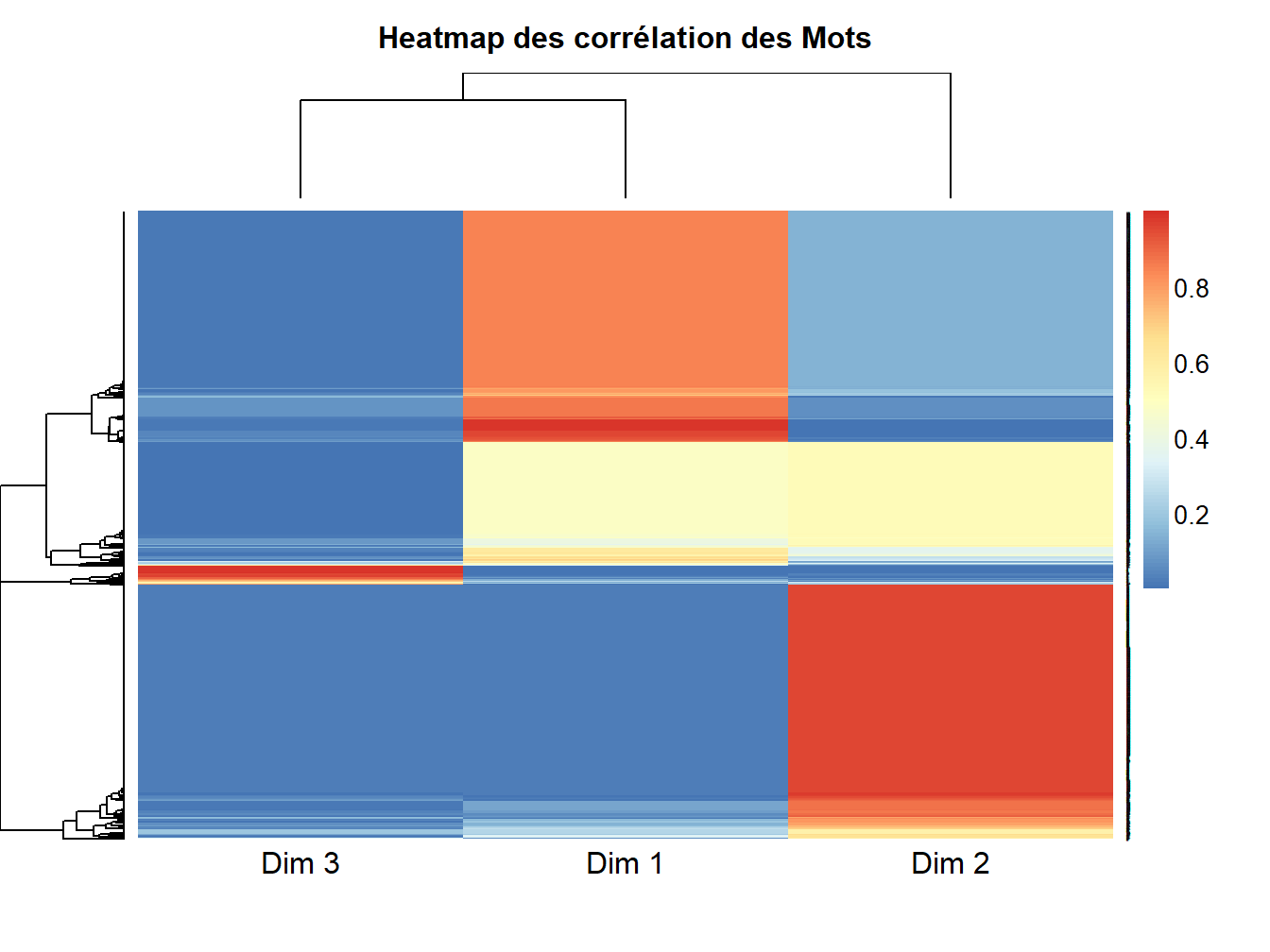
Figure 12.9: Heatmap des relations & contributions
On observe que les mots semblent bien reliés de manière différenciés aux facteurs. Les contributions varient et contrastent :
Les dimensions 2 et 1 semblent avoir le plus de mots corrélés dans des dimensions similaires.
La dimension 3 semble assez spécifique, et bien quelle soit corrélée de manière fabile avec les autres, une petite proportion de mots semble la refléter largement.
Une seconde matrice suscitant alors notre intérêt, est celle des Langages, associés aux dimensions :
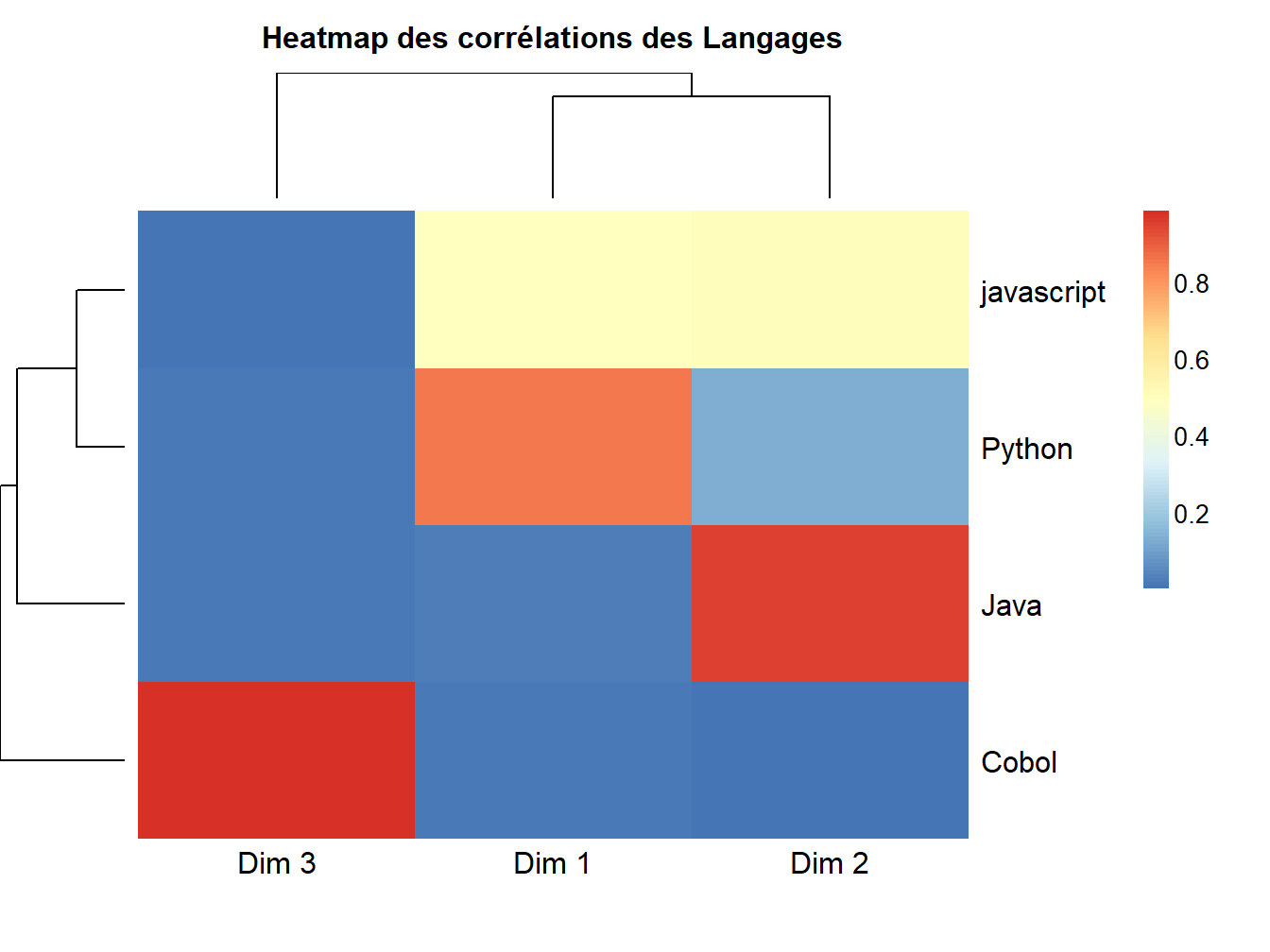
Figure 12.10: Heatmap des langages corrélés aux dimensions
Sans surprise, le petit groupe de mots identifiés préalablement correspond à une corrélation forte entre Cobol et la deuxième dimension.
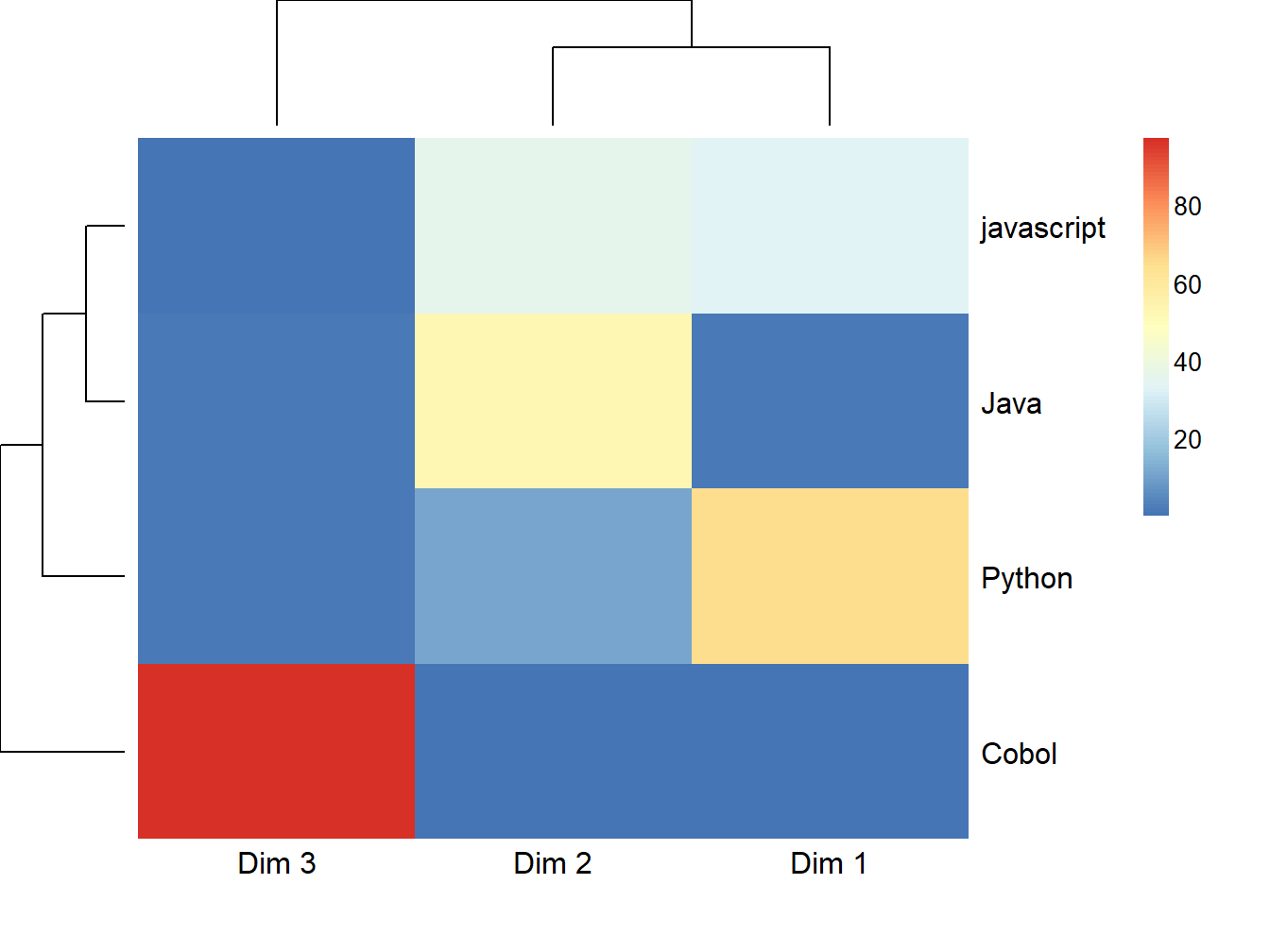
Figure 12.11: Heatmap des contribution des langages
Cobol est effectivement le langage qui semble le plus contribuer à la dimension 2, elle même représentée très fortement par un très petit nombre de Mots. Les matrices que nous manipulons sont rectangulaires. Dans ce cas précis, les deux matrices sont liées par \(k=3\) dimensions. On peut donc retrouver, dans une généralisation de la théorie de la décomposition en valeur singulière, cette matrice “probable” nommée \(S\), comme énoncé dans son théorème généralisé GSVD:
\[\begin{align*} S=\mathbf{U}\mathbf{D} \mathbf{V}^\top \end{align*} \]avec, \(U_{n}\) une matrice carrée tel que : \(U=n\) x \(k\) ; \(v=k\) x \(p\) cette fois…
###On cherche
u <- as.matrix(row$cos2)
v <- as.matrix(col$cos2)
###Par application du SVD, on transpose h afin de pouvoir faire le produit matriciel/croisé des matrices individus/dimensions & dimensions/variables
v <- t(v)
res <- as.data.frame(u%*%v)
###On visualise les mots croisés avec les variables
aheatmap(res,labRow = "")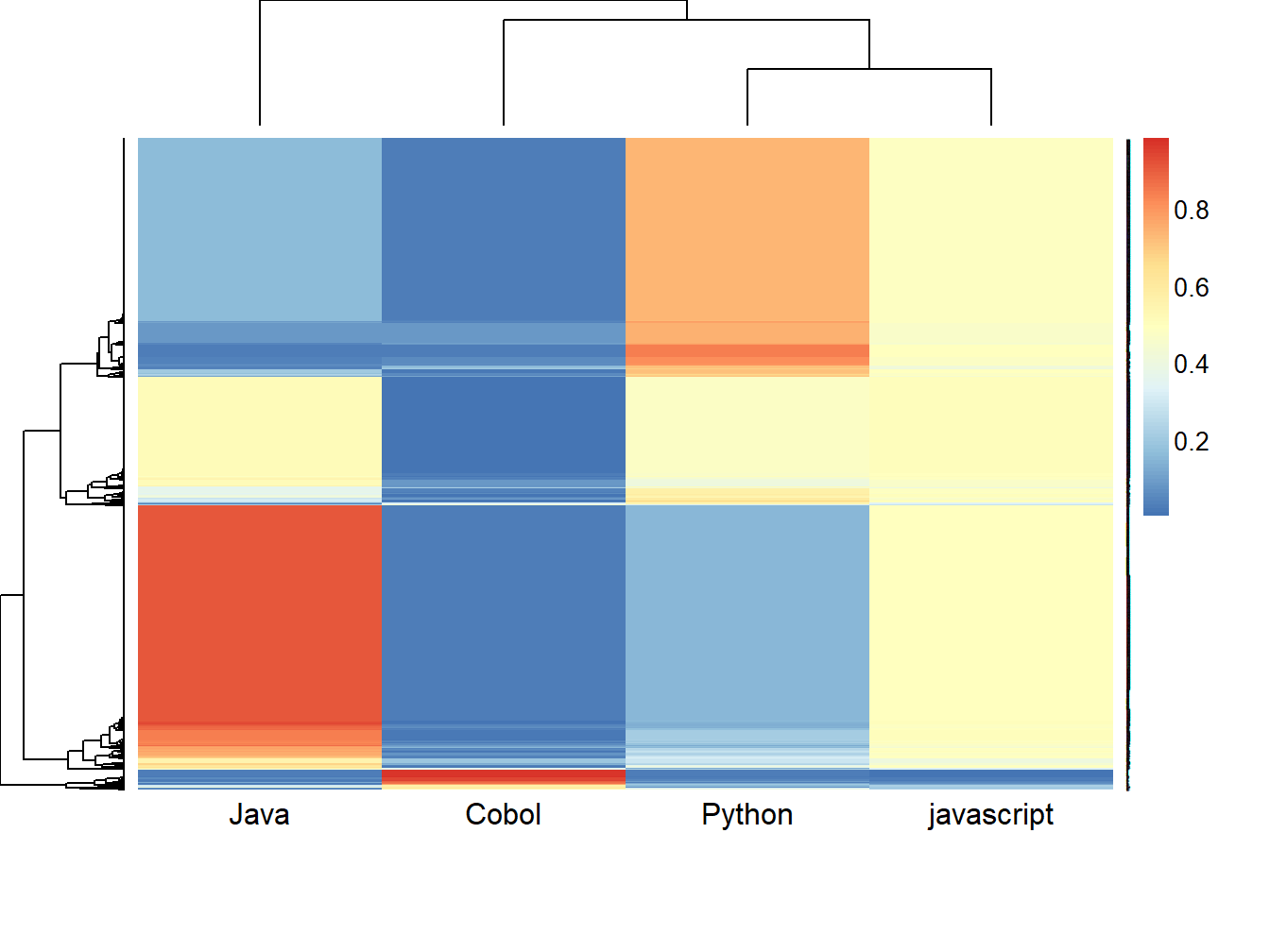
Figure 12.12: Double Clustering des lignes et colonnes
foo <- as.data.frame(res)
foo <- foo[1:3594,]
foocob <- foo%>%arrange(desc(Cobol))%>%head(30)
foo_synth <- rownames(foocob)
foo_synth <- as.data.frame(foo_synth)
colnames(foo_synth) <- "Cobol"
foojav <- foo%>%arrange(desc(javascript))%>%head(30)
foo_synth$javascript <- rownames(foojav)
fooJava <- foo%>%arrange(desc(Java))%>%head(30)
foo_synth$Java <- rownames(fooJava)
fooPyth <- foo%>%arrange(desc(Python))%>%head(30)
foo_synth$Python <- rownames(fooPyth)
foo_synth <- flextable(foo_synth)
foo_synth <- set_caption(foo_synth,"Mots les plus associés aux langages")
foo_synthCobol | javascript | Java | Python |
mauvais | ad | linl | pub |
donner | méthode | machinelearning | constater |
technologie | configuration | saison | free |
con | blog | introduction | apir |
croissant | gars | librairie | différent |
désuet | sécurité | expliquer | front |
mathlab | pays | livre | orienter |
bwahaha | suisse | condition | respecter |
currer | utile | faille | carré |
retir | lier | retourner | devops |
90 | outil | paraître | developers |
investissement | introduction | typescript | vérification |
développeur.eux | librairie | considérer | abonnement |
employabilité | expliquer | twitch | nouveauter |
spécialisation | livre | tailwindcss | vendredi |
rémunéré | condition | rendu | discussion |
vitesse | faille | variable | reste |
supérieur | retourner | choix | paris |
sgbd | paraître | côté | expertise |
âge | typescript | codinglife | prêt |
capitaine | considérer | équipe | radio |
decevoir | twitch | bot | all |
wiki | tailwindcss | contrat | démarrer |
transaction | rendu | sécurité | fil |
bancaire | variable | ouiir | toulouser |
it | framework | gogo | filter |
tre | compilation | assurer | connaissance |
spécifique | iot | cousin | assembly |
concret | github | mulhouser | enquête |
périmètre | react | jaaller | testing |
A cette étape, le double clustering ne nous renseigne que très peu. Il faut manipuler et filtrer les variables afin de récupérer les mots qui sont les plus représentatifs de chacun des langages. Le résultat épouse bien la réalité.
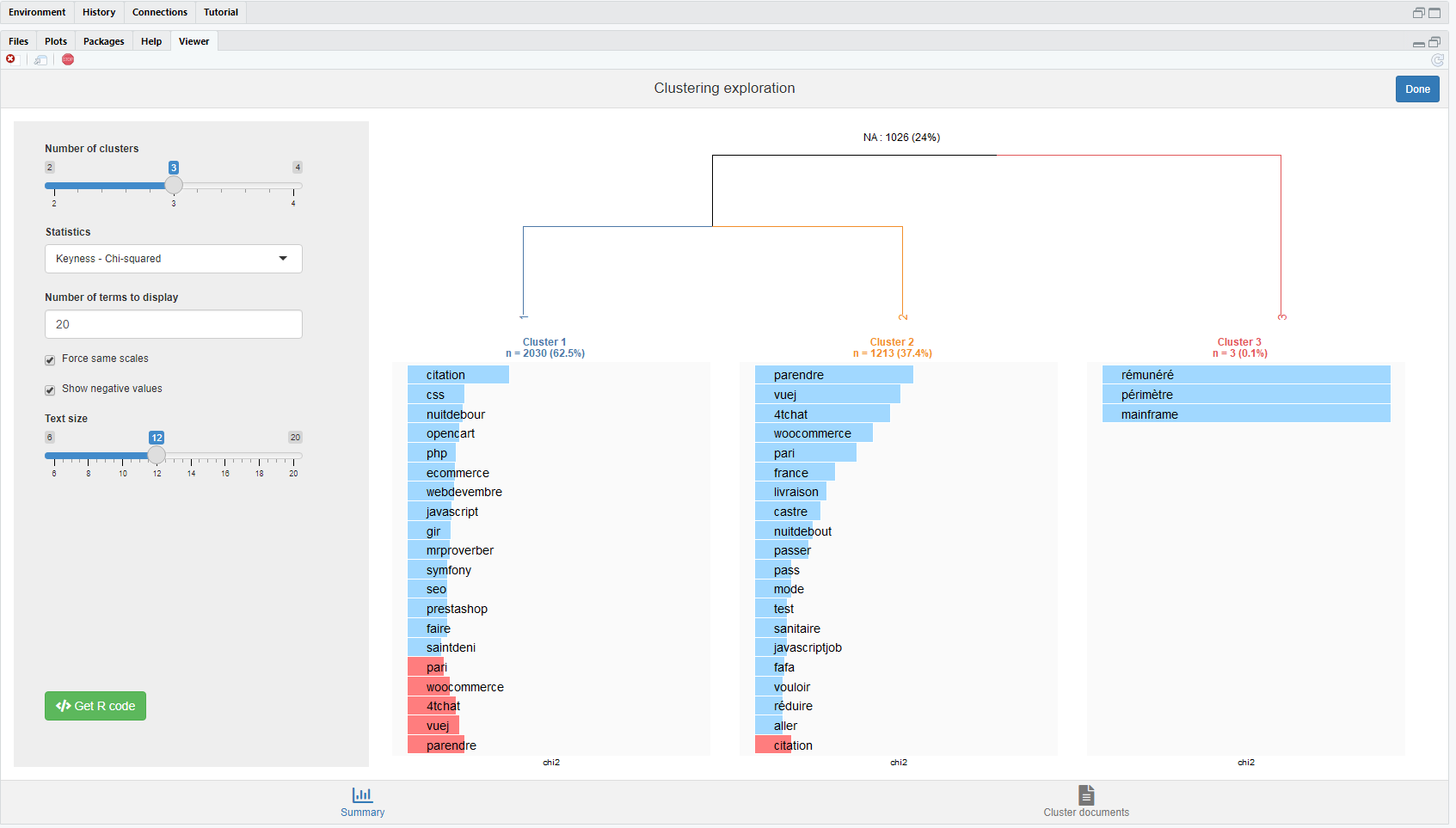
12.7.2.2 Le Modèle Rainette ou la méthode Reinert
Rainette est un package reposant sur le même principe qu’explor ou encore LDAvis et permet d’accélerer l’analyse exploratoire d’une fouille de texte. Afin d’être représenté dans le livre, nous mettons execution dynamique de cette application shiny
La méthode Reinert…
###On récupère les mots de notre tdm2, filtrée et nettoyée
vect_flt <- rownames(tdm2)
vect_mrq <- c("Cobol","javascript")
###On crée un sous ensemble composante les marques et les mots compris dand tdm2
df_corp <- df_trt_annot%>%select(lemma,Marque)%>%filter(lemma%in%vect_flt,Marque%in%vect_mrq)
###On crée un corpus pour pouvoir visualiser les données avec une seule docvars
foo <- corpus(df_corp, text_field = "lemma")
###On crée un corpus pour pouvoir visualiser les données avec une seule docvars
tok <- tokens(foo, remove_punct = TRUE)
###On crée un corpus pour pouvoir visualiser les données avec une seule docvars
dtm <- dfm(tok, tolower = TRUE)
res <- rainette(dtm, k = 4)
#rainette_explor(res, dtm, foo)