Chapitre 5 Explorer et visualiser le corpus
Un des meilleur conseils qu’on puisse donner, est de lire soi-même le texte avant de le confier aux machines.Comme dans le cas de grand corpus, il est difficile d’en lire l’ensemble, certains outils plus ou moins interactif, permettent de se donner rapidement une idée des contenus.
5.1 Kwic
Le premier réflexe dans la lecture d’un corpus est de chercher dans quels contextes sont utilisé des mots cibles. C’est l’objet d’une vieille technique les : Key word in context.
exemple
5.2 Explorer le corpus
Avant de procéder aux analyses du corpus, il est souvent utile de le représenter. On va utiliser le package Corpora explore à cette fin. Il permet de préparer un corpus et de le visualiser de manière interactive avec la génération d’une app shiny. Malheuresuement nous ne savons pas rendre compte de la dynamique de l’outil. On peut naviguer aisement dans l’ensemble de texte.
On va utiliser une collection de donnée préparée avec Manel Benzarafa de l’Université paris Nanterre, et qui comprend l’intégralité des résumés, auteurs etc.. relatifs aux articles publiés dans PMP. Une base bibliographique intégrale. 1025 articles la compose.
library(readr)
#install.packages("corporaexplorer")
library(corporaexplorer)
library(readr)
PMP <- read_csv("data/PMPLast.csv")
PMP<-PMP %>%
select(Key, Author, Title, Issue, 3, 11)
PMP<-PMP%>% rename(Text=6, Annee=5) %>%
filter(Text!="Null" & !is.na(Annee))
corpus <- prepare_data(PMP,
date_based_corpus =FALSE,
grouping_variable = "Annee", # change grouping variable
within_group_identifier = "Title",
columns_doc_info =
colnames(df)[1:4],
tile_length_range = c(2, 10),
use_matrix = FALSE
)
#explore(corpus)Dans la photo d’écran suivante, on teste les termes " politique" et “management”. Chaque tuile ( tile) représente un des 1025 abstracts qui composent le corpus. Les couleurs correspondent à la fréquence des deux termes.
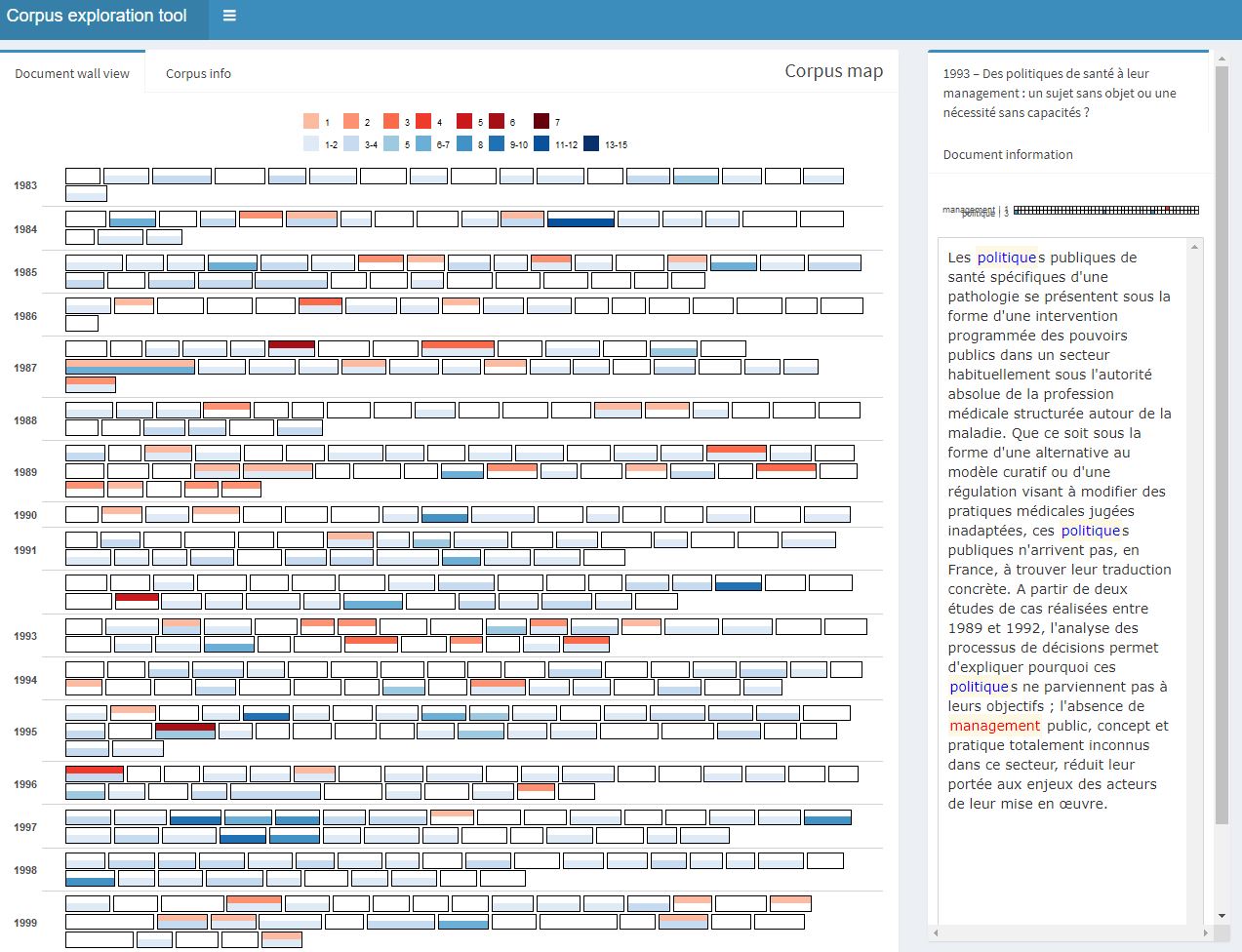
Exploration des abstracts de PMP