Chapitre 9 Tokenisation
9.1 Objectifs du chapitre
- Découper un texte en tokens
- Visualiser les n-grammes du texte
- Identifier les n-grammes pertinents et les transformer en tokens
9.2 Les outils
- Jeu de données : une citation de Max Weber et le corpus des commentaires laissés sur TripAdvisor concernant les hôtels polynésiens.
- Packages utilisés :
tokenizer;quanteda; ‘stopwords’
9.3 Introduction
L’étape intiale de toute analyse textuelle est de découper le texte en unités d’analyse, les tokens, ce qui transforme le texte écrit pour la compréhension humaine en données interprétables par l’ordinateur. Les tokens utilisés peuvent varier selon les objectifs de l’analyse et la nature du corpus, la granularité peut être plus ou moins fine. Les tokens peuvent ainsi être :
- des lettres : c’est l’unité insécable.
- des syllabes : ça permet de s’intéresser aux phonèmes.mais aussi d’extraire d’un mot les suffixes et préfixes, ainsi que les radicaux ( la racine du mot, ex : dés-espéré-ment).
- des mots : il s’agit du niveau le plus évident et le plus courant, que l’on privilégiera tout au long de ce livre
- des phrases : c’est l’unité de langage, lui correpond un argument, une proposition ; l’usage du point suivi d’un espace et d’une majuscule est assez général pour les identifier.
- des paragraphes : c’est une unité plus générale, qui souvent développe une idée.
- des sections, des chapitres, ou des livres : selon la nature des documents, cela permet de découper le corpus en sous-unités.
Les tokenizers sont les outils indispensables à cette tâche. Dans cet ouvrage, nous nous concentrons sur l’étude des mots. Lors de cette étude, un certain nombre de mots apparaissent de nombreuses fois, pour permettre de donner du sens au langage humain, mais ils ne portent pas en eux d’informations particulièrement pertinentes pour l’analyse : ce sont les stopwords, qu’il conviendra souvent d’éliminer.
Les n-grammes, quant à eux, représentent des suites de n tokens. Un unigramme est donc équivalent à un token, un bigramme est une suite de deux tokens, etc. L’identification des n-grammes permet de détecter des suites de tokens qui reviennent plus souvent que leur probabilité d’occurrences. Si l’on se concentre sur les mots, nous sommes alors face à une unité sémantique, comme on le comprend facilement avec le bigramme ‘Assemblée Nationale’.
9.4 Tokeniser un corpus
9.4.1 Les lettres
Commençons par un exemple simple, à l’aide d’une courte citation de Max Weber. On choisit les lettres pour unité de découpe, et l’on utilise le package ‘tokenizer’. Automatiquement, ‘tokenizer’ met le texte en minuscule et élimine la ponctuation
#Les données
MaxWeber <- paste0("Bureaucratie: le moyen le plus rationnel que l’on connaisse pour exercer un contrôle impératif sur des êtres humains.")
#On tokenise, plus on transforme en dataframe le résultat.
toc_maxweber<-tokenize_characters(MaxWeber)%>%
as.data.frame()%>%
rename(tokens=1)
#On compte pour chaque token sa fréquence d'apparition
foo<-toc_maxweber %>%mutate(n=1) %>%
group_by(tokens)%>%
summarise(n=sum(n))%>%
filter(n>0)
#On représente par un diagramme en barre cette distribution des occuences d'apparition, en classant les tokens par fréquence
ggplot(foo, aes(x=reorder(tokens,n), y=n))+
geom_bar(stat="identity", fill="royalblue")+
annotate("text", x=10,y=10, label=paste("nombre de tokens =", nrow(toc_maxweber)))+
coord_flip()+
labs(title = "Fréquence des tokens, unité = lettres",
x="tokens",
y="nombre d'occurences",
caption =" 'Bureaucratie: le moyen le plus rationnel que l’on connaisse pour exercer un contrôle impératif sur des êtres humains.' ")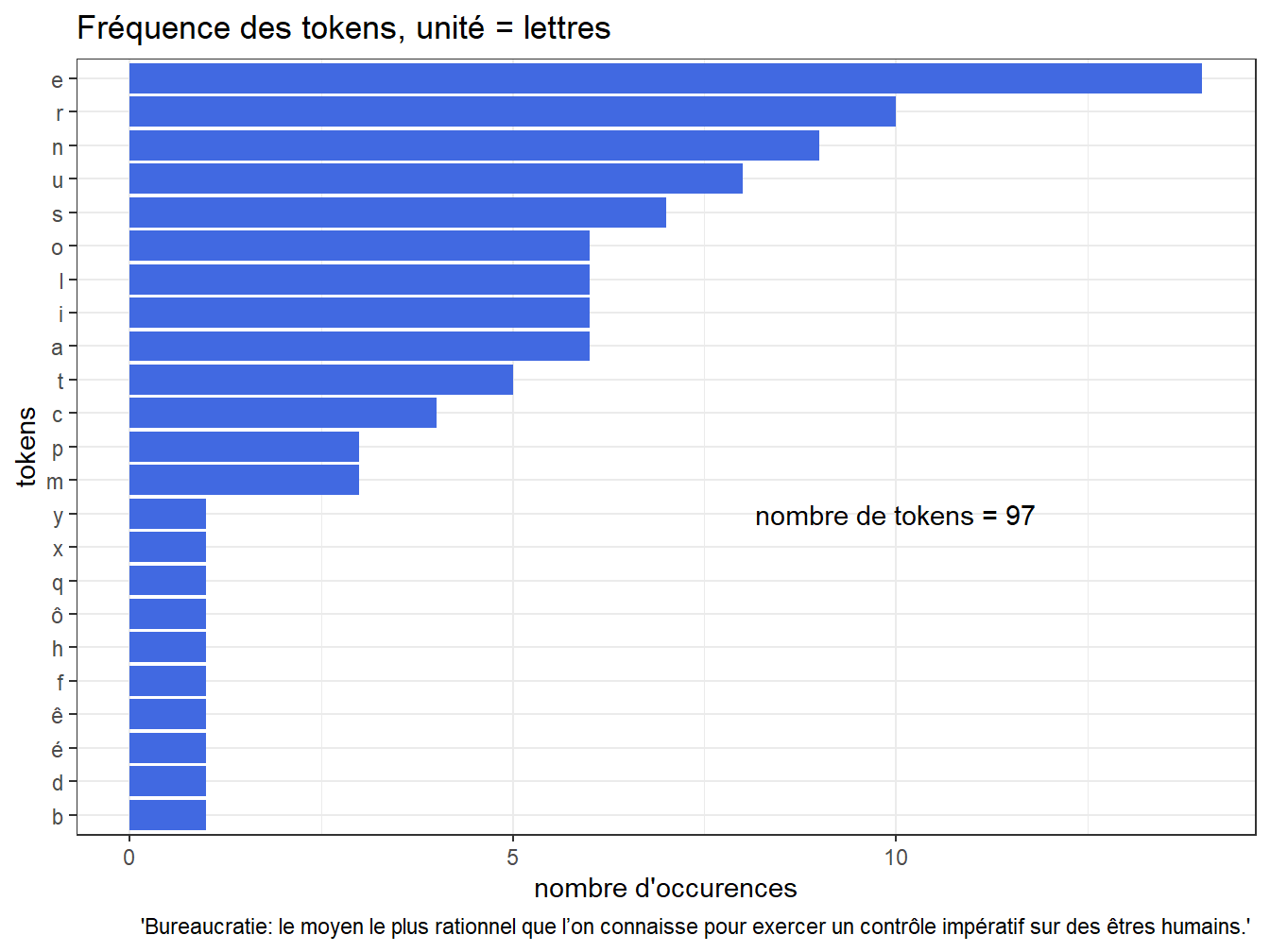
Figure 9.1: Distribution du nombre de lettres
9.4.2 Les mots
On refait la même opération, mais avec un texte complété. Il y a bien moins de mots que de lettres !
#Les données
MaxWeber <- paste0("Bureaucratie: le moyen le plus rationnel que l’on connaisse pour exercer un contrôle impératif sur des êtres humains. La bureaucratie est une forme d'organisation générale caractérisée par la prépondérance des règles et de procédures qui sont appliquées de façon impersonnelle par des agents spécialisés. Ces agents appliquent les règles sans discuter des objectifs ou des raisons qui les fondent. Ils doivent faire preuve de neutralité et oublier leurs propres intérêts personnels au profit de l’intérêt général.")
#On tokenise, plus on transforme en dataframe le résultat.
toc_maxweber<-tokenize_words(MaxWeber)%>%
as.data.frame()%>%
rename(tokens=1)
#On compte pour chaque token sa fréquence d'apparition
foo<-toc_maxweber %>%mutate(n=1) %>%
group_by(tokens)%>%
summarise(n=sum(n))
#On représente par un diagramme en barre cette distribution des occurrences, en classant les tokens par fréquence
ggplot(foo, aes(x=reorder(tokens,n), y=n))+
geom_bar(stat="identity", fill="royalblue")+
annotate("text", x=10,y=4, label=paste("nombre de tokens =", nrow(toc_maxweber)))+
coord_flip()+labs(title = "Fréquence des tokens, unité = mots", x="tokens", y="nombre d'occurences", caption =" 'Bureaucratie: le moyen le plus rationnel que l’on connaisse pour exercer un contrôle impératif sur des êtres humains.' ")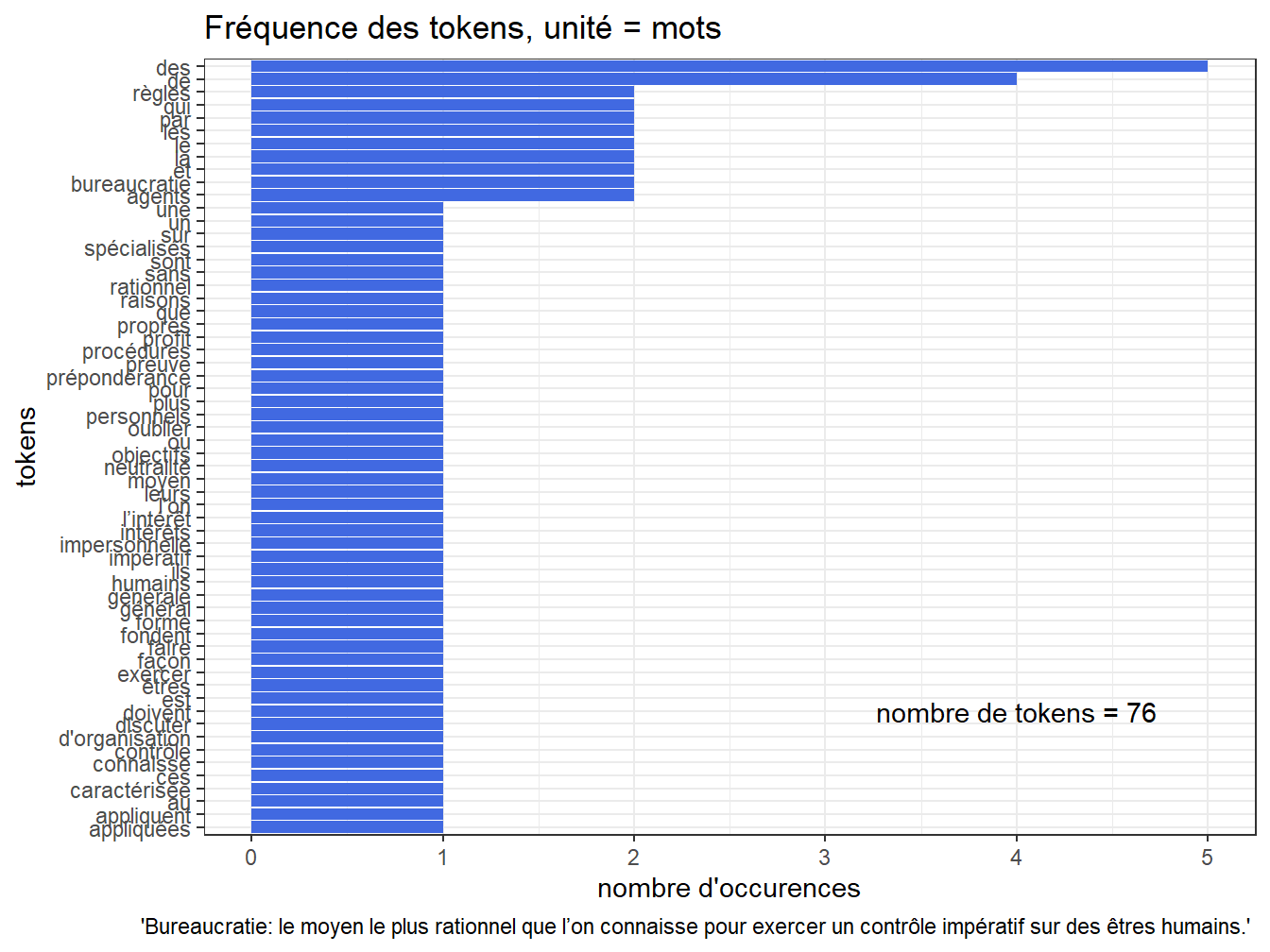
Figure 9.2: Distribution du nombre de mots
On constate que les deux mots les plus fréquents de cette citation sont un article indéfini et une préposition. Ces mots sont souvent superflus pour les analyses menées, il convient alors de les supprimer. C’est ce qu’on fait par la suite, en utilisant le package ‘stopwords’ qui comprend des listes de stopwords dans différentes langues.
#On tokenise et on enlève les stopwords, puis on transforme en dataframe le résultat.
toc_maxweber<-tokenize_words(MaxWeber, stopwords = stopwords("fr"))%>%
as.data.frame()%>%
rename(tokens=1)
#On compte pour chaque token sa fréquence d'apparition
foo<-toc_maxweber %>%mutate(n=1) %>%
group_by(tokens)%>%
summarise(n=sum(n))%>%filter(n>0)
#On représente par un diagramme en barre cette distribution des occurrences, en classant les tokens par fréquence
ggplot(foo, aes(x=reorder(tokens,n), y=n))+
geom_bar(stat="identity", fill="royalblue")+
annotate("text", x=10,y=1.5, label=paste("nombre de tokens =", nrow(toc_maxweber)))+
coord_flip()+labs(title = "Fréquence des tokens, unité = mots, stopwords éliminés", x="tokens", y="nombre d'occurences", caption =" 'Bureaucratie: le moyen le plus rationnel que l’on connaisse pour exercer un contrôle impératif sur des êtres humains.' ")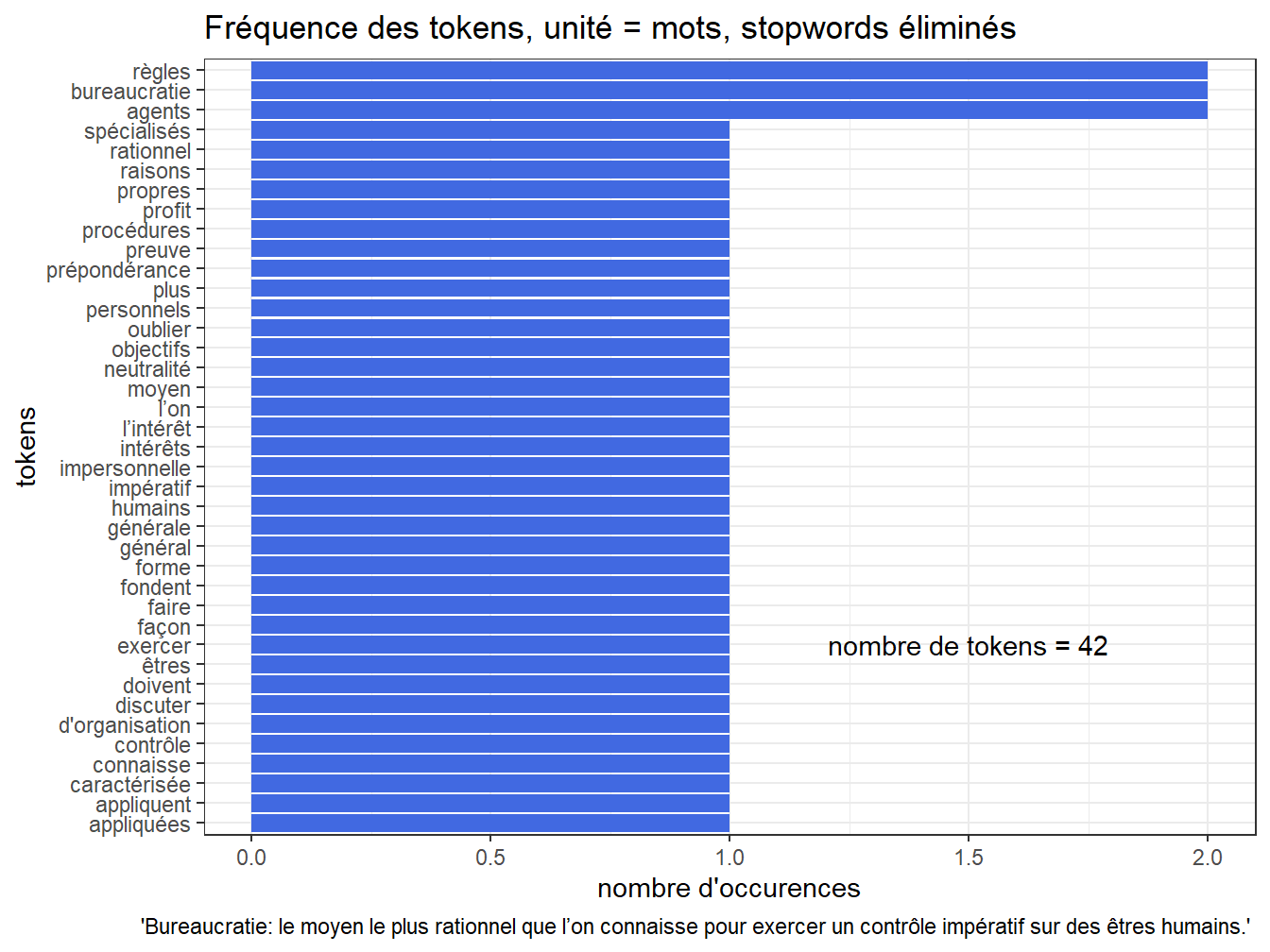
Figure 9.3: Distribution du nombre de mots, sans les stopwords
On peut également constater que certains mots sont proches, par exemple les deux derniers sur le graphiques précédents qui sont des déclinaisons du verbe appliquer. Il peut alors être pertinent de regrouper ces différentes formes verbales (comme un mot au singulier et au pluriel, au féminin et au masculin, ou conjugué sous différentes formes), pour faciliter l’analyse. C’est ce qu’on fait avec les opérations de stemming ou de lemmatisation, présentées au chapitre ??.
9.4.3 Les phrases
On reproduit les mêmes opérations, mais cette fois sur les phrases de l’exemple précédent.
tokens |
Bureaucratie: le moyen le plus rationnel que l’on connaisse pour exercer un contrôle impératif sur des êtres humains. |
La bureaucratie est une forme d'organisation générale caractérisée par la prépondérance des règles et de procédures qui sont appliquées de façon impersonnelle par des agents spécialisés. |
Ces agents appliquent les règles sans discuter des objectifs ou des raisons qui les fondent. |
Ils doivent faire preuve de neutralité et oublier leurs propres intérêts personnels au profit de l’intérêt général. |
9.5 N-grammes
Les n-grammes sont des séquences de n tokens, généralement consécutifs. Voici tout de suite un exemple sur les lettres2, allant de bigramme au trigramme :
toc_maxweber<-tokenize_character_shingles(MaxWeber,n=3, n_min=2) %>%
as.data.frame()%>%rename(tokens=1)
flextable(head(toc_maxweber, n=20))tokens |
bu |
bur |
ur |
ure |
re |
rea |
ea |
eau |
au |
auc |
uc |
ucr |
cr |
cra |
ra |
rat |
at |
ati |
ti |
tie |
foo<-toc_maxweber %>%mutate(n=1) %>%
group_by(tokens)%>%
summarise(n=sum(n))%>%filter(n>3)
ggplot(foo, aes(x=reorder(tokens,n), y=n))+
geom_bar(stat="identity", fill="royalblue")+annotate("text", x=5,y=11, label=paste("nombre de tokens =", nrow(toc_maxweber)))+
coord_flip()+labs(title = "Bigrammes et trigrammes des lettres", x="n-gramme", y="nombre d'occurences")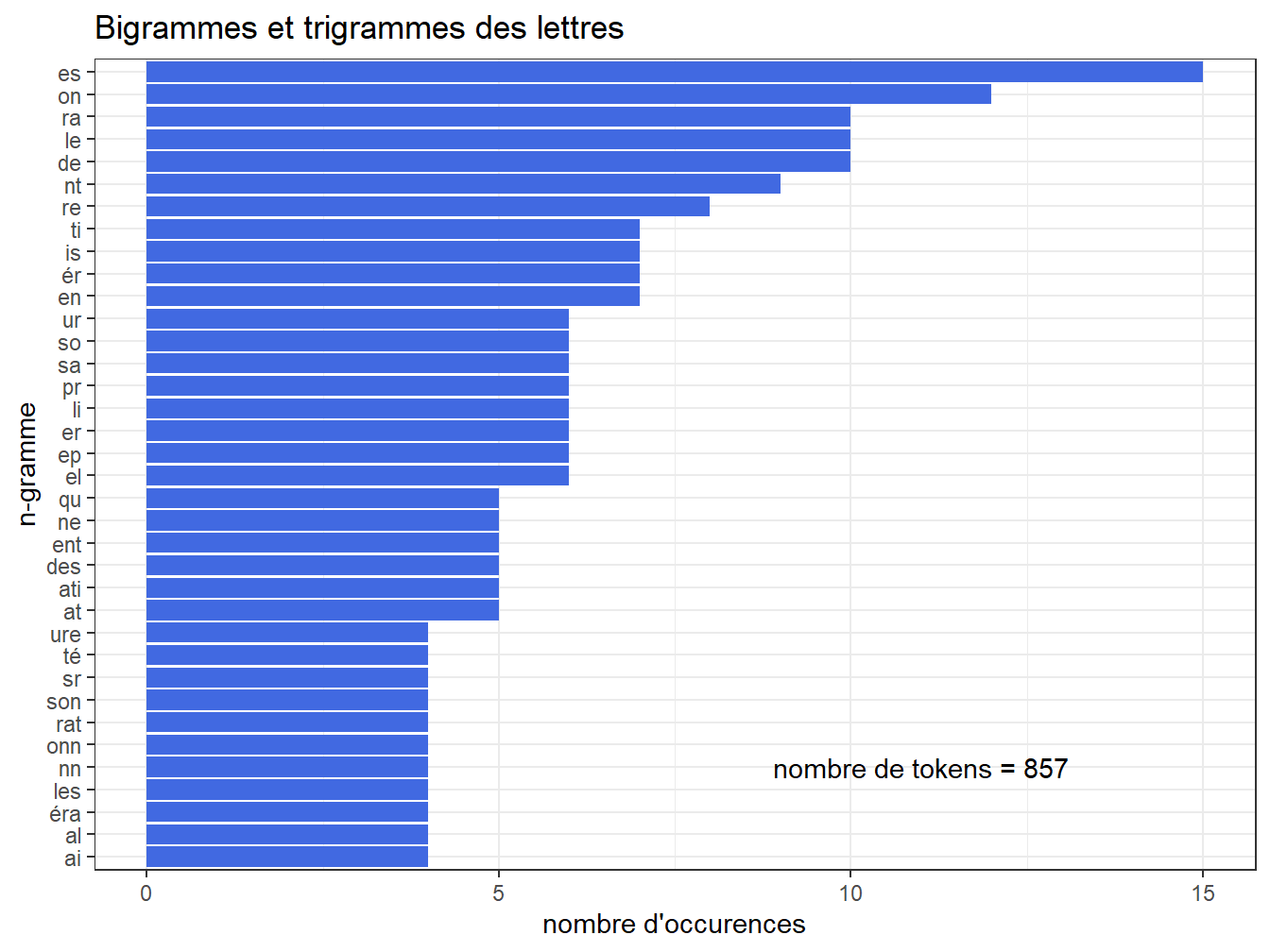
Figure 9.4: Bigrammes et trigrammes de lettres
On peut faire la même chose sur les mots, en éliminant les stopwords :
toc_maxweber<-tokenize_ngrams(MaxWeber,n=3, n_min=2, stopwords = stopwords('fr')) %>%
as.data.frame()%>%rename(tokens=1)
qflextable(head(toc_maxweber, n=19))tokens |
bureaucratie moyen |
bureaucratie moyen plus |
moyen plus |
moyen plus rationnel |
plus rationnel |
plus rationnel l’on |
rationnel l’on |
rationnel l’on connaisse |
l’on connaisse |
l’on connaisse exercer |
connaisse exercer |
connaisse exercer contrôle |
exercer contrôle |
exercer contrôle impératif |
contrôle impératif |
contrôle impératif êtres |
impératif êtres |
impératif êtres humains |
êtres humains |
On peut également s’intéresser aux n-grammes non directement consécutifs mais séparés par k tokens :
toc_maxweber<-tokenize_skip_ngrams(MaxWeber,n=3, n_min=2, k=2, stopwords = stopwords('fr')) %>%
as.data.frame()%>%rename(tokens=1)
qflextable(head(toc_maxweber, n=19))tokens |
bureaucratie moyen |
bureaucratie plus |
bureaucratie rationnel |
bureaucratie moyen plus |
bureaucratie moyen rationnel |
bureaucratie moyen l’on |
bureaucratie plus rationnel |
bureaucratie plus l’on |
bureaucratie plus connaisse |
bureaucratie rationnel l’on |
bureaucratie rationnel connaisse |
bureaucratie rationnel exercer |
moyen plus |
moyen rationnel |
moyen l’on |
moyen plus rationnel |
moyen plus l’on |
moyen plus connaisse |
moyen rationnel l’on |
Dans cet exemple, aucun n-gramme n’est répété, mais c’est rarement le cas avec des corpus plus importants. Dans ce cas, une forte répétition de n-grammes est un indice d’une unité sémantique composée de plusieurs tokens que l’on peut alors regrouper en un seul et même token. C’est ce que l’on verra dans la section suivante, avec l’utilisation de ‘quanteda’.
9.5.1 Propriétés statistiques des n-grammes
Sur la d’un base d’un corpus important on peut calculer les probabilité d’apparitions d’un n-gramme. C’est une ressource que fournit Google avec son Books Ngram Viewer.
application à la correction
9.6 Choisir des n-grammes pertinents
Dans ce livre l’unité principales d’analyse restera le mot. Mais nous savons, au moins intuitivement que certaines combinaisons de mots représentent des expressions qui ont la valeur d’un mot, une valeur sémantique, par exemple, l’expression “Assemblée Nationale”. Ces deux mots réunis constituent un syntagme, une unité de sens. La question qui se pose est alors de savoir comment les identifier dans le flot des n-grammes ?
La technique est simple : si deux mots se retrouvent dans un ordre donné plus fréquemment que ce que le produit de leurs probabilités d’apparition laisse espérer, c’est qu’ils constituent une expression. On peut imaginer faire un test du chi² pour décider si un couple de mots constitue une unité sémantique ou non.
Le package quanteda propose une bonne solution à ce problème avec la fonction collocation.
9.6.1 Créer les tokens avec ‘quanteda’
À partir du corpus des commentaires de TripAdvisor concernant les hôtels de Polynésie Française, on crée un objet de format token, dans lequel on a enlevé les stopwords. Mais pour que les n-grammes très fréquents restent des syntagmes signifiants, on laisse apparent les positions des stopwords, avec l’option ‘padding= TRUE’.
#les données
AvisTripadvisor<-read_rds("data/AvisTripadvisor.rds")
#création du corpus
corpus<-corpus(AvisTripadvisor,docid_field = "ID",text_field = "Commetaire")
head(corpus)## Corpus consisting of 6 documents and 21 docvars.
## 1 :
## "Tout est magnifique au Vahine island. Séjour de rêve avec un..."
##
## 2 :
## "Tout était parfait, notre meilleure expérience et plus belle..."
##
## 3 :
## "Un séjour magnifique, 3 jours époustouflants, accueillis cha..."
##
## 4 :
## "Vraiment beau, cadre idyllique personnel très attentionné. N..."
##
## 5 :
## "Au Vahiné Island on entre dans un monde parallèle où on ne s..."
##
## 6 :
## "Nous avons adoré notre séjour au Vahiné Island avec nos 3 en..."#transformation en objet token
tok<-tokens(corpus,remove_punct = TRUE, remove_symbols=TRUE, remove_numbers=TRUE)
head(tok)## Tokens consisting of 6 documents and 21 docvars.
## 1 :
## [1] "Tout" "est" "magnifique" "au" "Vahine"
## [6] "island" "Séjour" "de" "rêve" "avec"
## [11] "une" "équipe"
## [ ... and 22 more ]
##
## 2 :
## [1] "Tout" "était" "parfait" "notre" "meilleure"
## [6] "expérience" "et" "plus" "belle" "découverte"
## [11] "en" "Polynésie.Un"
## [ ... and 37 more ]
##
## 3 :
## [1] "Un" "séjour" "magnifique" "jours"
## [5] "époustouflants" "accueillis" "chaleureusement" "par"
## [9] "toute" "l'équipe" "du" "Vahine"
## [ ... and 27 more ]
##
## 4 :
## [1] "Vraiment" "beau" "cadre" "idyllique" "personnel"
## [6] "très" "attentionné" "Nous" "avons" "adoré"
## [11] "notre" "séjour"
## [ ... and 27 more ]
##
## 5 :
## [1] "Au" "Vahiné" "Island" "on" "entre" "dans"
## [7] "un" "monde" "parallèle" "où" "on" "ne"
## [ ... and 126 more ]
##
## 6 :
## [1] "Nous" "avons" "adoré" "notre" "séjour" "au"
## [7] "Vahiné" "Island" "avec" "nos" "enfants" "bungalow"
## [ ... and 77 more ]## Tokens consisting of 6 documents and 21 docvars.
## 1 :
## [1] "Tout" "" "magnifique" "" "Vahine"
## [6] "island" "Séjour" "" "rêve" ""
## [11] "" "équipe"
## [ ... and 22 more ]
##
## 2 :
## [1] "Tout" "" "parfait" "" "meilleure"
## [6] "expérience" "" "plus" "belle" "découverte"
## [11] "" "Polynésie.Un"
## [ ... and 37 more ]
##
## 3 :
## [1] "" "séjour" "magnifique" "jours"
## [5] "époustouflants" "accueillis" "chaleureusement" ""
## [9] "toute" "l'équipe" "" "Vahine"
## [ ... and 27 more ]
##
## 4 :
## [1] "Vraiment" "beau" "cadre" "idyllique" "personnel"
## [6] "très" "attentionné" "" "" "adoré"
## [11] "" "séjour"
## [ ... and 27 more ]
##
## 5 :
## [1] "" "Vahiné" "Island" "" "entre" ""
## [7] "" "monde" "parallèle" "où" "" ""
## [ ... and 126 more ]
##
## 6 :
## [1] "" "" "adoré" "" "séjour" ""
## [7] "Vahiné" "Island" "" "" "enfants" "bungalow"
## [ ... and 77 more ]#on transforme en document-features matrix pour des représentations graphiques
dfm<-dfm(tok,remove_padding=TRUE)
head(dfm)## Document-feature matrix of: 6 documents, 23,045 features (99.85% sparse) and 21 docvars.
## features
## docs tout magnifique vahine island séjour rêve équipe très chaleureuse cadre
## 1 1 1 1 1 1 1 2 1 1 1
## 2 2 0 0 0 0 0 1 2 0 0
## 3 1 1 1 1 1 0 0 0 0 0
## 4 1 1 0 0 1 0 0 1 0 1
## 5 2 1 0 1 0 1 0 4 0 0
## 6 0 1 0 1 2 1 0 0 0 0
## [ reached max_nfeat ... 23,035 more features ]#un nuage de mots rapide
textplot_wordcloud(dfm, max_words = 200, color = rev(RColorBrewer::brewer.pal(6, "RdBu")))
Figure 9.5: Mots les plus fréquents du corpus
9.6.2 Identifier les noms propres
On cherche ici à identifier les noms propres présents dans le corpus.
#on sélectionne les mots commençant par une majuscule
toks_cap <- tokens_select(tok,
pattern = "^[A-Z]",
valuetype = "regex",
case_insensitive = FALSE,
padding = TRUE)
#on cherche les collocations
tstat_col_cap <- textstat_collocations(toks_cap, min_count = 3, tolower = FALSE)
flextable(head(as.data.frame(tstat_col_cap)))collocation | count | count_nested | length | lambda | z |
Bora Bora | 155 | 0 | 2 | 7.159074 | 57.75427 |
Pearl Beach | 13 | 0 | 2 | 8.592055 | 23.25054 |
Jean Claude | 13 | 0 | 2 | 8.980729 | 22.41189 |
Tiputa Lodge | 13 | 0 | 2 | 7.129103 | 22.06886 |
Taha'a Island | 10 | 0 | 2 | 8.272921 | 20.98451 |
Nuku Hiva | 23 | 0 | 2 | 11.619165 | 20.66761 |
9.6.3 Composer des tokens à partir d’expressions multi-mots
Dans ce corpus, les noms propres correspondent aux noms des îles et des hôtels, et aux prénoms composés. La valeur du lambda montre la force de l’association entre les mots, on retiendra d’une manière générale un lambda au moins supérieur à 3 pour remplacer les tokens d’origine par leurs n-grammes.
toks_comp <- tokens_compound(tok, pattern = tstat_col_cap[tstat_col_cap$z > 3],
case_insensitive = FALSE)
head(toks_comp)## Tokens consisting of 6 documents and 21 docvars.
## 1 :
## [1] "Tout" "" "magnifique" "" "Vahine"
## [6] "island" "Séjour" "" "rêve" ""
## [11] "" "équipe"
## [ ... and 22 more ]
##
## 2 :
## [1] "Tout" "" "parfait" "" "meilleure"
## [6] "expérience" "" "plus" "belle" "découverte"
## [11] "" "Polynésie.Un"
## [ ... and 37 more ]
##
## 3 :
## [1] "" "séjour" "magnifique" "jours"
## [5] "époustouflants" "accueillis" "chaleureusement" ""
## [9] "toute" "l'équipe" "" "Vahine_Island"
## [ ... and 26 more ]
##
## 4 :
## [1] "Vraiment" "beau" "cadre" "idyllique" "personnel"
## [6] "très" "attentionné" "" "" "adoré"
## [11] "" "séjour"
## [ ... and 27 more ]
##
## 5 :
## [1] "" "Vahiné_Island" "" "entre"
## [5] "" "" "monde" "parallèle"
## [9] "où" "" "" "sait"
## [ ... and 125 more ]
##
## 6 :
## [1] "" "" "adoré" ""
## [5] "séjour" "" "Vahiné_Island" ""
## [9] "" "enfants" "bungalow" ""
## [ ... and 76 more ]dfm<-dfm(toks_comp, remove_padding=TRUE)
textplot_wordcloud(dfm, max_words = 200, color = rev(RColorBrewer::brewer.pal(6, "RdBu")))
Figure 9.6: Mots les plus fréquents du corpus
9.6.4 Identifier les autres concepts
Dans ce corpus, on peut aussi s’attendre à voir apparaître d’autres expressions multi-mots qui représentent des concepts, telles que “petit déjeuner”.
collocation | count | count_nested | length | lambda | z |
petit déjeuner | 769 | 0 | 2 | 7.510485 | 85.88487 |
très bien | 714 | 0 | 2 | 3.591647 | 76.20326 |
très bon | 422 | 0 | 2 | 4.072595 | 61.79011 |
très agréable | 374 | 0 | 2 | 4.200133 | 58.42280 |
grand merci | 167 | 0 | 2 | 5.650650 | 55.78169 |
passé nuits | 151 | 0 | 2 | 5.517906 | 53.58480 |
Au vue de la diversité des collocations, on choisit un lambda supérieur à 7 pour retenir les concepts les plus pertinents.
## Tokens consisting of 6 documents and 21 docvars.
## 1 :
## [1] "Tout" "" "magnifique" "" "Vahine"
## [6] "island" "Séjour" "" "rêve" ""
## [11] "" "équipe"
## [ ... and 22 more ]
##
## 2 :
## [1] "Tout" "" "parfait" "" "meilleure"
## [6] "expérience" "" "plus_belle" "découverte" ""
## [11] "Polynésie.Un" "grand_merci"
## [ ... and 33 more ]
##
## 3 :
## [1] "" "séjour" "magnifique" "jours"
## [5] "époustouflants" "accueillis" "chaleureusement" ""
## [9] "toute_l'équipe" "" "Vahine" "Island"
## [ ... and 26 more ]
##
## 4 :
## [1] "Vraiment" "beau"
## [3] "cadre_idyllique" "personnel_très_attentionné"
## [5] "" ""
## [7] "adoré" ""
## [9] "séjour" "attention"
## [11] "spéciale" ""
## [ ... and 22 more ]
##
## 5 :
## [1] "" "Vahiné" "Island" "" "entre" ""
## [7] "" "monde" "parallèle" "où" "" ""
## [ ... and 117 more ]
##
## 6 :
## [1] "" "" "adoré" "" "séjour" ""
## [7] "Vahiné" "Island" "" "" "enfants" "bungalow"
## [ ... and 74 more ]dfm<-dfm(toks_comp, remove_padding=TRUE)
textplot_wordcloud(dfm, max_words = 200, color = rev(RColorBrewer::brewer.pal(6, "RdBu")))
Figure 9.7: Mots les plus fréquents du corpus
9.7 Conclusion
Dans ce chapitre, nous avons vu comment découper un corpus en unités, les tokens. Nous avons abordé le sujet des n-grammes, et vu comment composer des tokens à partir de concepts multi-mots, identifiés par des n-grammes adjacents.
Le principe de ‘textcat’ est fondée sur ces n-grammes de lettre. Chaque langue se caractérise par une distribution particulière des n-grammes. Pour décider de l’appartenance d’un texte à une langue, si on dispose des profils de distribution, on compare la distribution des n-grammes du texte à ces références. On peut ainsi calculer une distance et attribuer le texte à la langue dont il est le plus proche.↩