Chapitre 2 Introduction
Depuis quelques temps déjà, le texte connaît une double révolution. La première concerne tout d’abord son système de production : il se produit désormais tant de textes que personne ne peut plus tous les lire, cela même en réduisant son effort à sa propre sphère d’intérêt et de compétence. La seconde, est quant à elle, plus propre aux transformations relatives à sa lecture, qui se retrouve être de plus en plus conditionnée et recommandée.
La production primaire de textes voit aujourd’hui son volume croître exponentiellement. Elle se compare à la transition moderne, où le texte était d’abord copié manuscritement, avant de connaître une recopie plus standardisée, associée à l’invention et l’essor de l’imprimerie. Ce qui était alors avant destiné à être reproduit, était le résultats d’un processus long et exigeant, qui permettait à un petit groupe de lettrés et d’imprimeurs de contrôler l’essentiel de ce qui pouvait être lu. En ce sens, la “révolution digitale” permet à un ensemble encore plus élargi d’individus, via des interfaces numériques simples, de confier sous forme d’écrits, leurs états d’âme, réflexions et autres opinions. Cette production se soumet donc à ceux qui en contrôlent les flux et en exploitent les contenus, les mettant en avant ou les écartant, définissant ainsi la composition de ce que chacun va pouvoir lire. La diffusion de cette production suit des lois puissances, c’est ainsi que la révolution de la lecture est venue avec les moteurs de recherche, et les pratiques de curations (ref) : une lecture sélectionnée et digérée par les divers moteurs et algorithmes de recommandations. (ref).
S’il ne fallait citer qu’un exemple, on pourrait évoquer la transformation radicale de la littérature scientifique, dont le niveau de production double aujourd’hui presque tous les dix ans. .http://blogs.nature.com/news/2014/05/global-scientific-output-doubles-every-nine-years.html
A cette production exponentiellement croissante, s’ajoute un effort d’inventaire. Des standards sont proposés, l’indexation a donné naissance à l’immatriculation systématique de la moindre note, l’interopérabilité est de mise, le réseau des co-citations se maintient en temps réel. Différents scores qualifient autant les articles que leurs auteurs, comme les revues qui les accueillent. Le monde de la recherche, processus par nature plus exploratoire, allant vers l’inconnu, est désormais totalement balisé et quantifié. Le volume généré est si grand, que la production automatique de résumés, revues bibliographiques et autres synthèses, se généralise avec un caractère de plus en plus indispensable.
Le Natural Langage Processing (en français Traitement Automatique du Langage) est au coeur de ces technologies, et se nourrit de plus en plus de l’intelligence artificielle. Nous en verrons de nombreux exemples à tous les stades du traitement : identifier la langue, mesurer le sentiment, isoler des sujets, calculer une relation syntaxique, évaluer une intention, détecter une tonalité…
Le NLP est aussi une ressource pour les chercheurs en sciences sociales, tant par les matériaux empiriques nouvellement mis à disposition, que par les méthodes d’analyse proposées. C’est une mouvemennt qui affecte toutes les sciences humaines. L’emballement de la production de texte génère une nouvelle matière d’étude pour les sociologues, gestionnaires, économistes, et psychologues.
Si dans ce manuel, on choisit de présenter les différentes facettes de ce qui s’appelle le “TAL”, le “NLP”, le “Text Mining”, dans une approche procédurale qui suit les principales étapes du traitement des données, nous rendrons compte à chaque étape des techniques disponibles, que l’on illustrera d’exemples. Nous suivrons ici une approche plus fidèle au processus de traitement des données, lequel peut connaître tant une stratégie inférentielle et exploratoire (Quelles informations sont utiles au sein d’un corpus de texte ?), qu’une stratégie plus hypothético-déductive. Sur ces questions portant sur son usage, nous choisissons d’être délibéremment agnostiques, préférant présentement de rester au niveau plus technique et procédural de ces outils de recherche.
2.1 Une réflexion ancienne et un nouveau champ méthodologique
On ne doit pas se faire aveugler par l’éclat d’une apparente nouveauté de ces méthodes. Les techniques d’aujourd’hui dépendent d’idées semées depuis longtemps dans au moins deux champs de recherche académiques : la linguistique et l’informatique. On peut alors en synthétiser l’idée avec cette figure annotée. elle en exprime deux veines principales. La première, est une tension du champs entre la langue comme structure, quand la seconde considère le langage en tant que capacité et usage.
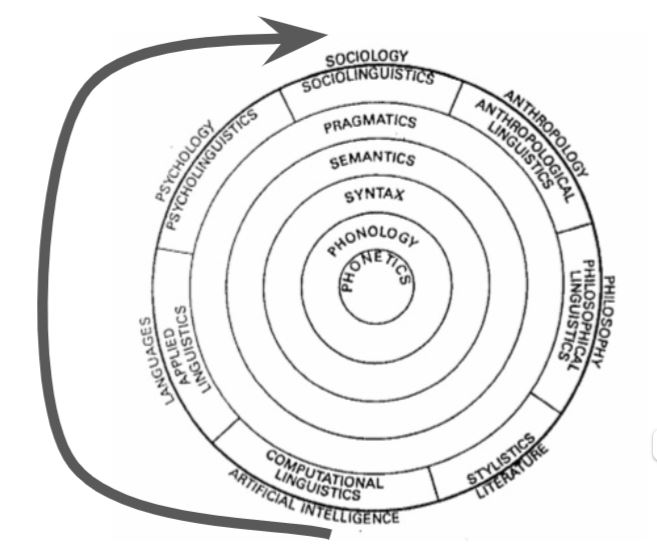
Les pratiques et techniques que nous allons étudier ne tombent pas de Mars, mais résultent de plusieurs flux de pensées qui se croisent, se confortent et amènent l’énergie pour créer un nouveau courant dans le champs étendu de l’étude de la langue et du langage.
Penser la langue est un effort constant qui a commencé il y a de nombreuses années, certainement avec les sophistes, et l’idée qu’en maniant le langage, il est possible de convaincre, en construisant une logique propre (protagoras, Diogène…). Pour les sophistes : plier le langage à ses intérêt est une première sciences du langage qui témoigne d’une connaissance des dispositifs les plus efficaces. Pas sûr que cette discipline ait trouvé un “episteme” reconnu, mais elle n’en reste pas moins commune et contemporaine : c’est l’art de la publicité. La rhétorique n’est pas une discipline morte, elle se développe de manière concrète dans toute les agences publicitaires.
Donnons quelques points de repère en commençant par quelques définitions préliminaires, avant de se concentrer sur trois idées essentielles qui vont prospérer avec le développement de la linguistique computationnelle et de l’intelligence artificielle. Ces trois idées sont relatives aux principales branches de la linguistique : à savoir la syntaxe, la sémantique et la pragmatique. Nous resterons ici silencieux sur la phonologie (étude de la formation des sons et de la phonétique) dont l’importance est considérable quand il s’agit de traiter la production et les interactions orales. Pour ne donner qu’un exemple, la prosodie (le rythme données aux phrases) est un objet d’étude essentiel dans les courants de recherches en informatique affective.
2.1.1 Langue, langage et texte parole
La langue se définit comme un ensemble de règles plus ou moins formelles que constitue une parole : ce qui se dit de l’un à l’autre ou de l’un aux autres. Le langage est la capacité à produire cette parole. La constitution de cette parole par l’écriture constitue le texte. Le miracle du passage de la parole au signe est celui du symbole.
Parmi les distinctions terminologiques proposées par Ferdinand de Saussure au début de siècle dernier, autour de la langue, du langage et de la parole se sont révélées particulièrement pertinentes et restent toujours utilisées de nos jours.
Le Langage : faculté inhérente et universelle de l’humain de construire des langues (des codes) pour communiquer. (Leclerc 1989:15) Le langage réfère à des facultés psychologiques permettant de communiquer à l’aide d’un système de communication quelconque. Le langage est inné.
La Langue : système de communication conventionnel particulier. Par « système », il faut comprendre que ce n’est pas seulement une collection d’éléments mais bien un ensemble structuré composé d’éléments et de règles permettant de décrire un comportement régulier (Pensez à la conjugaison de verbes en français par exemple). La langue est acquise.
Le langage et la langue s’opposent donc par le fait que la langue est la manifestation d’une faculté propre à l’humain, qui n’est autre que le langage.
La Parole: une des deux composantes du langage qui consiste en l’utilisation de la langue. La parole est en fait le résultat de l’utilisation de la langue et du langage, et constitue ce qui est produit lorsque l’on communique avec nos pairs.
Le texte : Il est la transcription de la parole, même si le plus souvent, sa production est directe sans étape intermédiaire de traduction du langage oral.
2.1.2 Syntaxe et grammaire générative
Nous nous réfèrerons ici à Chomsky et sa grammaire générative. En dépit de leur très grande diversité, le projet s’appuit sur l’idée qu’un nombre fini de règles doit produire une infinité d’énoncés. Une grammaire est générative dans la mesure où elle possède cette propriété. L’analyse est ainsi tournée vers la compétence, et le linguiste s’intérresse à l’idéal qu’un locuteur qui, en connaissant ces règles, serait en mesure de produire une pluralité de discours.
Observant que les enfants apprennent, enracinant le phénomène linguistique dans la cortalisation du langage, il apporte une idée forte et structuraliste d’une équivalence entre les langues.
Sous la lumière deTesnière et de ses arbres syntaxiques, les treebanks contemporains s’inscrivent dans cette perspective et nourrissent les analyseurs (parser) syntaxiques du langage naturel qui constituent désormais la première couche d’un traitement de données textuelles.
La grammaire générative a conduit la linguistique dans un tournant formel où la langue est étudiée indépendemment de ses locuteurs. On pourra méditer sur le “pourquoi” des algorithmes génératifs contemporains de deep learning (le fameux GPT3) qui réussissent à former des phrases syntaxiquement correctes mais absurdes.
2.1.3 Sémantique : La conception distributionnelle
La tradition lexicologique file le lexique comme une affaire ancienne. Le français est aidé par des institutions fondamentales : le littré, l’académie française et les premiers dictionnaires des éditeurs. Pour étudier un langage il faut se rapporter à des formes stables, les dictionnaires les documentent et renseignent ces normes pour les coder.
Un moment clé a été de penser le signe, Saussure apporte alors cette idée fondamentale que dans le symbole, le signe et le signifiant sont les deux faces d’une même monnaie, qu’il existe une relation entre l’artefact et l’idée. En d’autres termes; il est possible qu’un signe particulier puisse signifier une idée : c’est un penseur de la correspondance.
Selon Saussure, la langue est le résultat d’une convention sociale transmise par la société à l’individu et sur laquelle ce dernier n’a qu’un rôle accessoire. Par opposition, la parole est l’utilisation personnelle de la langue (toutes les variantes personnelles possibles: style, rythme, syntaxe, prononciation, etc.). Le changement de la langue relève d’un individu mais son acceptation relève de la communauté et des institutions. ex.: le verbe « jouer » conjugué «jousent » est pour l’instant à considérer comme une variante individuelle (parole), une exception, et il le demeurera tant qu’il ne sera pas accepté dans la communauté (les locuteurs du français dans ce cas-ci). Sa conception du signe répond à cette approche conventionnelle : la dualité du signe comme signifiant et signifié est opérée.
Dans le traitement des données textuelles le “signifié” est le terme cible de l’analyse, pour en découvrir son signifié on se tourne vers son contexte : l’ensemble des signifiés. C’est une idée ancienne qu’a proposé Firth dans les années 30. (Firth 1957) construisant ainsi la genèse du paradigme distributionnel. Un mot trouve son sens dans ceux qui lui sont le plus associés. C’est, dans cette veine, le contexte qui donne alors le sens.
(Zipf) L’idée de quantifier le langage n’est pas particulièrement innovante, et ce, moins encore s’il s’agît d’en compter les occurences et les cooccurences des mots. Un vaste mouvement s’est formé dans les années soixante autour de la lexicologue, stimulé par l’école française de l’analyse de données. Le descendant de ce mouvement se retrouve dans l’excellent iramuteq de l’équipe de Toulouse, précédé par le fameux Alceste, et maintenant durablement intégré dans le package R Rainette.
Nous y consacrerons un chapitre complet sur le plan technique. Il reste important de souligner que cette école française de l’analyse textuelle ne se limite pas au comptage d’entités. Un logiciel comme trope qui d’ailleurs ne connait aucun équivalent dans l’écosystème que nous allons explorer, manifeste aussi cette inventivité, où s’exprime pleinement la logique distributionnelle.
2.1.4 L’approche pragmatique : les fonctions et acte du langage
Si la grammaire générative se tourne délibéremment plutôt vers la compétence et ignore la performance, c’est à dire la production d’énoncés par les humains en situation d’interaction plus que sur les effets de l’énoncé lui-même, un autre courant de la linguistique s’est emparé de la question, le courant dît de la pragmatique du langage.
Le grand classique de ce courant est la théorie des fonctions du language, qui sous-tendent la production d’un message : l’acte de parole, proposée par Jakobson. Inspiré par la cybernétique, la structure de son modèle est celle d’un acte de communication. Jackobson identifie les éléments de l’évènement discursif (speech event) et les fonctions qui lui sont associées. Pour le paraphraser, un LOCUTEUR envoie un MESSAGE à un ou plusieurs INTERLOCUTEUR(S) qui, afin d’être compris, requiert un CONTEXTE dont les acteurs de l’évènement discursif sont capables de saisir et de verbaliser, ce qui suppose l’existence d’un CODE au moins partiellement commun et d’un CONTACT, canal physique ainsi que d’une connection psychologique. On listera alors, au sens du théoriocien (“Linguistics and Poetics” 1981)àlire ici
- La fonction référentielle ou représentative (aussi dénommée sémiotique ou symbolique), où l’énoncé donne l’état des choses , où le message dénote un contexte. Jakobson emploie aussi les termes de dénotatif ou cognitif.
- La fonction expressive (émotive), où le sujet exprime son attitude propre à l’égard de ce dont il parle.
- La fonction conative, lorsque l’énoncé vise à agir sur le destinataire : elle s’exprime grammaticalement par l’impératif ou le vocatif.
- La fonction phatique, empruntée à Malinoswki où l’énoncé révèle les liens ou maintient les contacts entre le locuteur et l’interlocuteur ;
- La fonction métalinguistique ou métacommunicative, qui fait référence au code linguistique lui-même, qu’il soit théorisé ou internalisé par le locuteur, comme la prose de Monsieur Jourdain.
- La fonction poétique, lorsque l’énoncé est doté d’une valeur en tant que tel, valeur apportant un pouvoir créateur et dont Jakobson illustre avec l’exemple de la jeune fille qui a l’habitude de désigner Harry par “Horrible Harry” sans pouvoir expliquer pourquoi il ne serait pas l’odieux, le dégoûtant, ou le terrible Harry, alors que sans s’en rendre compte, elle emploie une paronomasie/alliteration : la ressemblance phonologique et prosodique des mots produit un puissant effet poétique.
John Langshaw Austin s’intéressant à la fonction conative développe le
concept d’acte de langage, introduisant l’idée fondamentale que les
actes de langage (la production d’un énoncé) ne sont pas uniquement
destinés à décrire le monde tel qu’il est, mais bien à agir sur le monde
par le biais du locuteur et du destinataire. Parler devient alors
également, faire. La théorie des actes de langage est d’abord une
catégorisation des différents actes. Il distingue trois types de
réalisations s’opérant au travers du langage :
Le locutoire : cette dimension du langage est réalisée à partir du
moment où un énoncé, est juste grammaticalement, dans les règles de la
langue dans laquelle il est émis. Prononcer à table, la phrase :
“Est-ce-qu’il y a du sel ?”, est une construction langagière correcte,
et se réalise dans sa première dimension. Cependant, dans la théorie
linguistique de John Langshaw Austin, le message convoyé par un énoncé
va au-delà de son sens immédiat, et s’intègre dans une seconde
fonction.
L’illocutoire : L’exemple précédent n’a pas, du seul fait de sa
formulation, uniquement pour fonction de s’informer sur la présence de
sel dans la maison (ou dans le plat, contenu locutoire de l’énoncé). Il
exprime plutôt que l’on voudrait saler son plat (fonction illocutoire)
et se traduit généralement par le fait que l’un des convives réagisse,
par exemple en passant la salière au locuteur. Ce faisant, le langage
performe un troisième niveau de discours, qu’Austin nomme la dimension
perlocutoire.
Le perlocutoire : Cette dimension finale se conjugue donc avec les deux
précédentes, mais son produit n’est pas commutatif, dans le sens où les
actions et interprétations sujettes de notre énoncé 1 dépendent des
fonctions plus basses de ces derniers, et s’enracinent également dans le
contexte de ceux-ci et d’éléments plus ou moins extra langagiers. Cette
idée est au cœur des sousbassements de la théorie des actes de langage
d’Austin, qui se détache donc fortement d’un langage uniquement
communicatif, au détriment d’une vision de ce dernier comme un outil
plus performatif que descriptif. Dire devient alors faire, car le
langage agit et transforme l’univers des interlocuteurs.
Genette et l’intertextualité, le palimpseste. c’est une question de
sens, le sens d’un texte vient de ses prédecesseurs et de ceux à qui ils
se réfèrent. Les auteurs au travers des textes se répondent l’un
l’autre, et ce n’est pas dans leur contenu qu’on trouvera une vérité
mais dans le rapport qu’ils établissent avec leurs prédecesseurs, par
l’appareil des notes et des bibliographies, des références et mises en
perspectives. Cette approche vient questionner l’apparente et rassurante
téléologie naturelle que chacun est tenté de voir, dans la remise en
continuité d’éléments qui sont alors détachés de leurs contextes de
production.
- La narrativité
2.1.5 La linguistique computationnelle
Les points de contact entre linguistique et informatique se produisent en rapport à diverses questions pratiques, portées sur le traitement et la computation d’éléments langagiers recensés selon des sources tant orales qu’écrites, pour diverses finalités opérationnelles. (traductions, analyses, transcriptions, synthèses…)
Les apports de la fouille de données
les nomenclatures
une convergence nécessaire
Le monde des bibliothèques et celui de la GED.
2.2 Les facteurs de développement de l’usage en science sociale
Ces développements sont favorisés par un environnement fertile où trois facteurs se renforcent mutuellement. Ils conduisent à l’élaboration de nouvelles méthodes.
- La naissance et généralisation de langues informatiques universelles
- L’emergence de vastes ensembles de données textuelles
- La naissance d’une communauté épistémique, de pratique et de
2.2.1 Une lingua franca
Le premier facteur de développement est l’expansion de la programmation orientée objet (POO). Plus spécifiquement dans le cas de la manipulation des données, deux langages de programmation se distinguent particulièrement, dans un usage proprement statistique pour R et plus généraliste en ce qui concerne Python. Le propre de ces langages est, prenons le cas de R, de permettre d’accéder à des interfaces et fonctions mathématiques, dont un ensemble cohérent pour réaliser certaines tâches peut être rassemblé dans une bibliothèque appelée “package” ou “librairie”. Ces bibliothèques de fonctions se chargent en mémoire facilement via la commande R suivante : library(nomdupackage). On dispose désormais de milliers de packages (17 788 sur le CRAN) destinés à résoudre un nombre incalculable de tâches. Une petite représentation ci-dessous témoigne de l’évolution exponentielle des outils mis à dispositions de la communauté R :
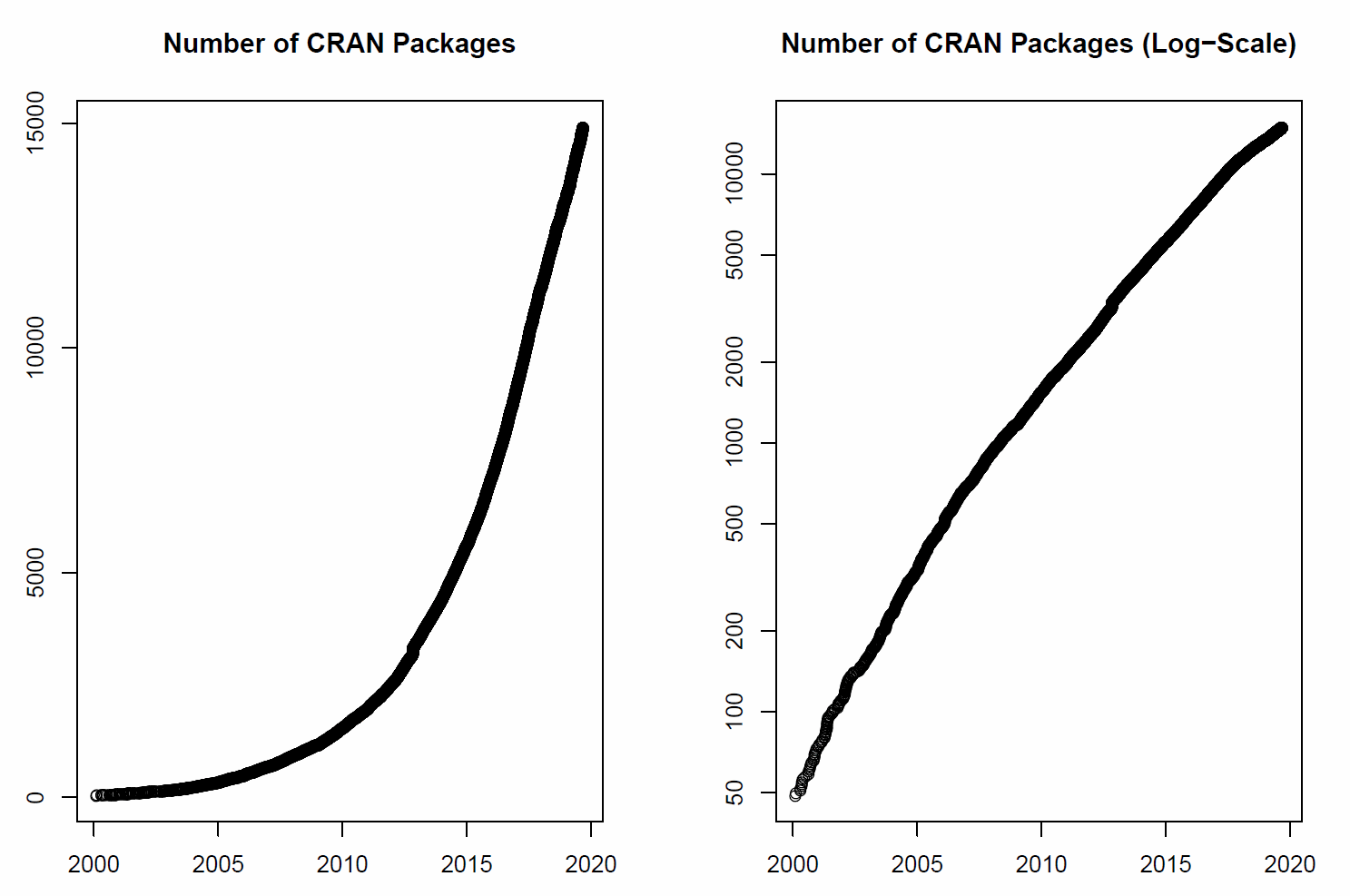
hornik
Développer et concevoir le code d’une analyse revient ainsi à jouer avec un immense jeu de briques, similaires aux Lego de notre enfance, dont de nombreuses pièces bas niveau sont déjà pré-moulées. D’un point de vue pratique, les lignes d’écritures sont fortement simplifiées, permettant à un chercheur non spécialisé en programmation d’effectuer simplement des opérations complexes. En retour, cette facilitation de l’analyse abonde le stock de solutions.
2.2.2 La multiplication des sources de données.
Le second facteur d’évolution est la multiplication des sources de données et leur facilité d’accès.
- Le contenu écrit des réseaux sociaux,
- Les rapports d’activités des entreprises,
- Les compte-rendus archivés de réunion,
- Les avis des consommateurs sur les catalogues de produits,
- Les articles et les revues scientifiques,
- Les livres numériques…
Les sources les plus évidentes sont proposées par les bases d’articles de presse telles que presseurop ou factiva. Les bases de données bibliographiques sont dans la même veine particulièrement intéressantes et pensées pour ces usages.
Les données privées, et en particulier celles des réseaux sociaux, même si un péage doit être payé pour accéder aux plateformes via différentes APIs, popularisent le traitement de données massives.
Les forums et sites d’avis de consommateurs sont pour les sociologues de la consommation et les spécialistes du comportement de consommation une ressource directe et précieuse.
Le mouvement des données ouvertes (open data) proposent et facilitent l’accès à des milliers de corpus de données : grand débat, European Survey…
2.2.3 Une communauté
Le troisème facteur de développement , intimement lié au premier, est la constitution d’une large communauté de développeurs et d’utilisateurs qui se retrouvent aujourd’hui dans des plateformes diverses. Le savoir, autrement dit des codes commentés se trouvent dans une varété importante de lieux :
- Des plateformes de dépôts telles que Github, qui rassemblent une
trentaine de millions de développeurs et data scientists.
- Des plateformes de Q&A (question et réponses) telles que Stalk Over Flow,
- Des tutoriaux de toute sortes : cours, vidéos et autres Mook
- Des blogs ou des fédérations de blogs (BloggeR),
- Des revues (Journal of Statistical Software) et de bookdown.
Des ressources abondantes sont ainsi disponibles et facilitent l’auto-formation des chercheurs et des data scientists, en proposant des ressources pour la résolution de leurs problèmes pratiques. Quiconque n’arrive pas à résoudre un problème a une bonne chance de trouver la solution d’un autre, à un degré de circonstances près. Elles sont d’autant plus utiles que certaines règles ou conventions s’imposent progressivement pour fluidifier l’échange et les projets individuels :
La principale démarche est alors celle de l’exemple reproductible.
La seconde est le maintien d’une éthique du partage qui encourage à partager le code, et dont une littérature importante étudie l’effet positif sur les performances économiques et la durabilité [rauter]. Les externalités de réseaux y sont fortes.
Toutes les conditions sont réunies pour engendrer une effervescence créative. Python ou R, sont dans cet univers en rapide expansion, les langues véhiculaires qui favorise une innovation constante. Les statistiques de Github en témoigne : près de 50 millions d’utilisateurs, 128 millions de “repositories” et 23 millions de propriétaires.
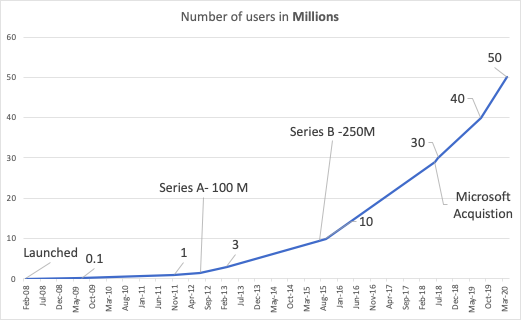
source
voir aussi https://towardsdatascience.com/githubs-path-to-128m-public-repositories-f6f656ab56b1
2.4 Un nouvel objet :
On pourrait croire qu’avec des données massives et des techniques “intelligentes” nous assistons à un retour du positivisme qui bénéficierait enfin des instruments de mesures et de calculs ayant permis à certains chercheurs au plus proche de la matière des succès majeurs. Sans nul doute, l’administration de la preuve va être faciliter par ces techniques et va encourager l’evidence based policy (REF) afin de résoudre en partie la crise de la réplication et de la reproductibilité des travaux de recherche.
Cependant, à mesure que se développe l’appareillage de méthode et de données, moins l’on peut supposer que l’observateur reste neutre. En effet, ni les téléscopes géants, ni les synchrotron, n’affectent les galaxies lointaines ou les atomes proches. Le propre des données que l’on est amené à étudier est de résulter de la confrontation d’un système d’observation (certains préfèrent alors parler de surveillance), à un agent, doué de buts, d’une connaissance, de biais, et de ressources. Le dispositif de mesure est en lui-même performatif. L’exemple le plus évident est celui des systèmes de notation, qui sous prétexte de transparence donne la distribution des répondants précédents. L’agent qui va noter choisit la valeur en fonction d’une norme apparente - la note majoritaire- et de sa propre intention - se manifester ou se confondre à la foule.
Pour se donner une idée plus précise de ce mouvement, examinons quelques publications récentes dans les champs qui nous concernent.
2.4.1 Sociologie et histoire
classes sociales avec word to vec en sociologie (Kozlowski, Taddy, and Evans 2019).
L’article révolution française [PNAS)
On citera cependant jean-baptiste Coulmont et son obstination à étudier les entités nommées, prénoms et autres marqueurs culturels de l’identité et des classes.
et au luxembourg
2.4.2 Psychologie
Très tôt la psychogie s’est intéressée au langage, pas seulement comme produit des processus psychologiques, mais comme expression de ceux-ci.
Dès les années 1960 dans le champ de la psychologie de l’éducation, doué d’une forte motivation positiviste, s’est posée la question de la mesure de la difficulté d’un texte pour un niveau d’éducation donné. La mesure de la lisibilité des textes s’est alors développée, profitant à d’autre secteurs tels que ceux de la propagande. Dans cette même perspective, l’approche scientifique de la richesse lexicographique comme concept représentant les compétences a à son tour développé de nouvelles instrumentations.
James W. Pennebaker a développé son approche à partir de l’étude des traumas; donnant une grande importance à la production discursive des patients. Sa contribution majeure est l’établissement d’un ensemble de dictionnaires destinés à mesurer des caractéristiques du discours. Un instrument qu’on présentera dans le chapitre 7 (à vérifier)(Tausczik and Pennebaker 2010).
Son approche se poursuit en psychiatrie avec l’analyse des troubles du langage, et a connu un coup d’éclat avec la demonstration que l’analyse des messages sur les réseaux sociaux comme facebook permet de détecter des risques de dépression.(Eichstaedt et al. 2018).
2.4.3 Management
La finance et l’analyse du sentiment
Dans le champ du management, on trouvera des synthèses pour la recherche en éthique (Lock and Seele 2015), en comportement du consommateur (Humphreys and Wang 2018) en management public (Anastasopoulos, Moldogaziev, and Scott 2017) ou en organisation (Kobayashi et al. 2018) ,
2.4.4 Economie
economie des brevets intervention des institutions mesure de l’innovation
2.5 Des comptables à l’industrie de la langue
La situation nouvelle qui semble être la notre consiste dans le fait que la parole qui disparaissait avant comme emportée par le vent, laisse désormais des traces et s’enregistre. L’ironie est qu’au titre de la protection de la vie privée, cet enregistrement systèmatique doit être mis à notre disposition. On a le choix : rien n’en faire, les détruire, ou bien encore les donner, afin de bénéficier de son potentiel de connaissance. Nous sommes passé de la parole au texte. Si seule la parole de Dieu et celle des chants étaient transcrites, c’est désormais aussi celle du vulgum. Si sa précision reste incertaine, son volume quant à lui a gagné de nombreuses échelles.
Cette matière ne s’organise plus dans les papyrus, tablettes d’argiles et autres manuscrits, ni même dans les livres sués par les callygraphieurs, elle s’incruste dans un édifice de plus en plus complexe d’interfaces textuelles et vocales. La parole est comme absorbée par les machines. Elle ne s’envolent plus avec le vent, elle se sédimente dans des data center, nouveaux monolithes modernes. Le langage a acquis une dimension matérielle qu’il n’a presque jamais connu. Il gagne de l’autonomie avec les systèmes génératifs : chat bots, transcriptions, traductions, résumés.
L’histoire se définit selon son écriture. [Daniel Gaxie, La raison Graphique] L’écriture est le produit d’une société de procès-verbal, de comptabilité et cela se poursuit. Voilà qui facilite le travail de l’historien, du sociologue et de l’économiste.
Dans les années 90 s’est dessinée une société de l’information, sauvage jusqu’ à Napters, et le rêve du peer to peer, elle s’est socialisée dans les années 2000, platformisée dans les années 2010, généralisée pour la décennie qui nous concerne. Toute cette architecture s’appuie sur les données qu’on y injecte, et au premier rang, y siège le texte, la transcription automatique de la parole, dans une recodification constante et des traitements de plus en plus hyperconcentrés.
2.6 Conclusion
Le point d’entrée qu’est la technique est privilégié dans ce manuel. Pour autant, l’on se donnera des espaces de réflexion, d’interrogation, des espaces epistémologiques (Comment étudier le langage par le langage ?) ainsi que des espaces plus anthropologiques (quelle est l’origine et la spécificité du langage humain en dépit de ses innombrables variétés ?).
Une première parenthèse est expérientielle, c’est en faisant que nous avons découvert une autre écriture. L’expérience de ce livre, qu’on partage avec de nombreux utilisateurs de ces nouveaux outils, est celle d’une écriture programmatique, performative. Ecrire c’est faire, les meta-langage transforment la transcription de la parole en une nouvelle connaissance. On peut agir sur la parole, sur le texte, le tordre, le presser, le décoder . On peut lire les foules.
Les langages tels que la linguistique classique étudie sont verbaux, d’autres sont iconiques, architecturaux, graphiques, chorégraphiques, musicaux. Elles se rencontre dans le flux d’une parole qui associe le texte à l’image dans des rapports d’illustations et de commentaires, jouant du contrepoint à travers les médias.
Par le texte, le sociologue, l’économiste ou le gestionnaire veulent co-prendre, ou comprendre, la génèse et la détermination des choix. Etudions donc le texte.
L’acte de parole se réalise dans un lieu à un moment, avec des protagonistes, dans une atmosphère, avec une histoire, les mots qui s’en échappent ne sont que des traces, autant que des photographies. Ces données se sédimentent dans les grands bassins du cloud hybride et dans les corpus constitués historiquement et méthodiquement.
References
Anastasopoulos, Lefteris Jason, Tima T. Moldogaziev, and Tyler Scott. 2017. “Computational Text Analysis for Public Management Research.” SSRN Electronic Journal. https://doi.org/10.2139/ssrn.3269520.
Eichstaedt, Johannes C., Robert J. Smith, Raina M. Merchant, Lyle H. Ungar, Patrick Crutchley, Daniel Preoţiuc-Pietro, David A. Asch, and H. Andrew Schwartz. 2018. “Facebook Language Predicts Depression in Medical Records.” Proceedings of the National Academy of Sciences 115 (44): 11203–8. https://doi.org/10.1073/pnas.1802331115.
Firth, J. R. 1957. “A Synopsis of Linguistic Theory 1930-55.” Studies in Linguistic Analysis (Special Volume of the Philological Society) 1952-59: 1–32.
Humphreys, Ashlee, and Rebecca Jen-Hui Wang. 2018. “Automated Text Analysis for Consumer Research.” Edited by Eileen Fischer and Linda Price. Journal of Consumer Research 44 (6): 1274–1306. https://doi.org/10.1093/jcr/ucx104.
Kobayashi, Vladimer B., Stefan T. Mol, Hannah A. Berkers, Gábor Kismihók, and Deanne N. Den Hartog. 2018. “Text Mining in Organizational Research.” Organizational Research Methods 21 (3): 733–65. https://doi.org/10.1177/1094428117722619.
Kozlowski, Austin C., Matt Taddy, and James A. Evans. 2019. “The Geometry of Culture: Analyzing the Meanings of Class Through Word Embeddings.” American Sociological Review 84 (5): 905–49. https://doi.org/10.1177/0003122419877135.
“Linguistics and Poetics.” 1981. In Poetry of Grammar and Grammar of Poetry, 18–51. De Gruyter Mouton. https://doi.org/10.1515/9783110802122.18.
Lock, Irina, and Peter Seele. 2015. “Quantitative Content Analysis as a Method for Business Ethics Research.” Business Ethics: A European Review 24 (July): S24–S40. https://doi.org/10.1111/beer.12095.
Tausczik, Yla R., and James W. Pennebaker. 2010. “The Psychological Meaning of Words: LIWC and Computerized Text Analysis Methods.” Journal of Language and Social Psychology 29 (1): 24–54. https://doi.org/10.1177/0261927X09351676.